
Photo by Tobias Fischer on Unsplash
👋 前言
数据库是每个应用程序的基石之一。它是你存储应用程序所需记忆、稍后运算或显示给线上其他用户看的所有内容的地方。在数据库变大之前,一切都很有趣,直到你的应用程序开始变慢,因为你试图一次读取并渲染 1,000 篇文章。好吧,你是个聪明的工程师对吧?你很快地用一个“显示更多”按钮修补了这个问题。几周后,你遇到一个新的 Timeout 错误!你前往 Stack Overflow,但很快发现 Ctrl 和 V 因为过度使用而停止工作了 🤦 在没有更多选择的情况下,你实际上开始调试,并意识到每次用户打开你的应用程序时,数据库都会返回超过 50,000 篇文章!我们现在该怎么办?

为了防止这些可怕的情况,我们应该从一开始就意识到风险,因为准备充分的开发人员永远不需要冒险。这篇文章将准备让你使用 offset(偏移量) 和 cursor pagination(游标分页) 来对抗与数据库相关的性能问题。
“预防胜于治疗。” - 本杰明·富兰克林
📚 什么是分页?
分页是当查询任何包含超过几百条记录的数据集时采用的一种策略。多亏了分页,我们可以将我们的 大型数据集 分割成我们可以逐步读取并显示给用户的 区块(或页面),从而减少数据库的负载。分页还解决了客户端和服务器端的许多性能问题!如果没有分页,你将不得不加载整个聊天记录,只为了阅读发送给你的最新消息。
现今,分页几乎已成为必需品,因为每个应用程序都很可能处理大量的数据。这些数据可以是任何东西,从用户生成的内容、管理员或编辑添加的内容,到自动生成的审计和日志。一旦你的列表增长到超过几千个项目,你的数据库将花费太长时间来解决每个请求,你的前端速度和可访问性就会受到影响。至于你的用户,他们的体验看起来会像这样。

现在我们知道什么是分页了,我们该如何实际使用它?为什么它是必要的?
🔍 分页的类型
有两种被广泛使用的分页策略 - offset 和 cursor。在深入研究并学习关于它们的一切之前,让我们看看一些使用它们的网站。
首先,让我们访问 GitHub 的 Stargazer 页面,注意标签是怎么写 5,000+ 而不是一个绝对数字的?此外,他们使用的是 Previous(上一页) 和 Next(下一页) 按钮,而不是 标准页码。

现在,让我们切换到 Amazon 的产品列表,注意确切的结果数量 364,以及你可以点击 1 2 3 … 20 的 所有页码 的 标准分页。

很明显,两家科技巨头无法就哪种解决方案更好达成一致!为什么?好吧,我们需要使用开发人员讨厌的一个答案:因为视情况而定。让我们探索这两种方法,以了解它们的优点、限制和性能影响。
Offset pagination(偏移量分页)
大多数网站使用 Offset 分页,因为它的 简单性 以及对用户来说分页是多么 直观。要实现 Offset 分页,我们通常需要两条信息:
limit- 要从数据库读取的行数offset- 要跳过的行数。Offset 就像页码,但周围有一些数学运算(offset = (page-1) * limit)
要获取数据的第一页,我们将 limit 设置为 10(因为我们希望页面上有 10 个项目)并将 offset 设置为 0(因为我们希望从第 0 个项目开始计算 10 个项目)。结果,我们将获得十行。
要获取第二页,我们保持 limit 为 10(这不会改变,因为我们希望每一页包含 10 行)并将 offset 设置为 10(返回从第 10 行开始的结果)。我们继续这种方法,从而允许最终用户对结果进行分页并查看他们的所有内容。
在 SQL 世界中,这样的查询将写成 SELECT * FROM posts OFFSET 10 LIMIT 10。
一些实现 Offset 分页的网站也会显示最后一页的页码。他们是怎么做到的?除了每一页的结果外,他们还倾向于返回一个 sum 属性,告诉你总共有多少行。使用 limit、sum 和一点数学运算,你可以使用 lastPage = ceil(sum / limit) 计算最后一页的页码。
虽然这个功能对用户来说很方便,但开发人员在扩展这种类型的分页时会遇到困难。看着 sum 属性,我们已经可以看到计算数据库中所有行的确切数量可能需要相当长的时间。除此之外,数据库中的 offset 是以一种 循环遍历行以知道应该跳过多少行 的方式实现的。这意味着我们的 offset 越高,我们的数据库查询需要的时间就越长。
Offset 分页的另一个缺点是它不适合 实时数据 或 经常变化的数据。Offset 说明了我们想要跳过多少行,但没有考虑到 行的删除 或新的 行被创建。这样的 offset 可能导致显示 重复的数据 或某些 数据丢失。
Cursor pagination(游标分页)
Cursor 是 Offset 的继承者,因为它们解决了 Offset 分页所有的问题 - 性能、数据丢失 和 数据重复,因为它不依赖于像 Offset 分页那样的 行的相对顺序。相反,它依赖于由数据库 创建和管理 的索引。要实现 Cursor 分页,我们将需要以下信息:
limit- 与之前相同,我们希望在一页上显示的行数cursor- 列表中参考元素的 ID。如果你正在查询上一页,这可以是第一个项目,如果查询下一页,这可以是最后一个项目。cursorDirection- 用户是点击了 Next 还是 Previous(之后还是之前)
当请求 第一页 时,我们不需要提供任何东西,只需要 limit 10,说明我们想要获取多少行。结果,我们得到了我们的十行。
要获取下一页,我们使用 最后一行 的 ID 作为 cursor,并将 cursorDirection 设置为 after。
同样地,如果我们想去 上一页,我们使用 第一行 的 ID 作为 cursor,并将 direction 设置为 before。
相比之下,在 SQL 世界中,我们可以将查询写为 SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC。
使用 cursor 而不是 offset 的查询性能更好,因为 WHERE 查询有助于 跳过不需要的行,而 OFFSET 需要 迭代它们,导致 全表扫描。如果你在 ID 上设置适当的索引,使用 WHERE 跳过行会变得 甚至更快。在主键的情况下,索引是默认创建的。
不仅如此,你 不再需要担心 行被 插入 或 删除。如果你使用的是 10 的 offset,你会期望在你当前页面之前正好有 10 行。如果这个条件不满足,你的查询将返回 不一致的结果,导致数据 重复 甚至 丢失行。如果任何 在你当前页面之前的 行被 删除 或 添加了新行,就会发生这种情况。Cursor 分页通过使用你读取的 最后一行的索引 来解决这个问题,它 确切地知道从哪里开始寻找,当你请求更多时。
这并不全是阳光和彩虹。如果你需要自己在后端实现它,Cursor 分页 是一个非常复杂的问题。要实现 Cursor 分页,你将需要在查询中使用 WHERE 和 ORDER BY 子句。此外,你还需要 WHERE 子句来根据你的需求条件进行过滤。这很快就会变得非常复杂,你可能会得到一个巨大的嵌套查询。除此之外,你还需要为你需要查询的所有字段创建索引。
太棒了!我们通过切换到 Cursor 分页 摆脱了 重复 和 丢失数据!但我们还剩下一个问题。由于你 不应该 向用户暴露 递增的数值 ID(出于安全原因),你现在必须维护 每个 ID 的哈希版本。每当只需要查询数据库时,你可以通过查看保存这些配对的表将此字符串 ID 转换为其数值 ID。如果这个 行丢失 怎么办?如果你点击 Next 按钮,获取 最后一场的 ID,并请求下一页,但数据库找不到该 ID 怎么办?
这是一个非常罕见的情况,只有当你正要用作 cursor 的行的 ID 刚刚被删除时才会发生。我们可以通过 尝试之前的行 或 重新读取早期请求的数据 来用新的 ID 更新最后一行来解决这个问题,但所有这些都带来了全新的复杂性水平,开发人员需要理解一堆新概念,例如 递归 和 适当的状态管理。值得庆幸的是,像 Appwrite 这样的服务会处理这个问题,所以你可以简单地将 Cursor 分页作为一个功能使用。
🚀 Appwrite 中的分页
Appwrite 是一个开源的后端即服务 (Backend-as-a-Service),它通过为你的核心后端需求提供一组 REST API,抽象化了构建现代应用程序所涉及的所有复杂性。Appwrite 处理用户认证和授权、数据库、文件存储、云函数、Webhooks 等等!如果有任何遗漏,你可以使用你最喜欢的后端语言扩展 Appwrite。
Appwrite 数据库让你存储任何需要在用户之间共享的基于文本的数据。Appwrite 的数据库允许你创建多个集合(表)并在其中存储多个文档(行)。每个集合都有配置的属性(字段),为你的数据集提供适当的架构。你还可以配置索引以使你的搜索查询更具性能。读取数据时,你可以使用大量强大的查询、过滤它们、排序它们、限制结果数量以及对它们进行分页。所有这些都是开箱即用的!
让 Appwrite 数据库更棒的是 Appwrite 的分页支持,因为我们同时支持 Offset 和 Cursor 分页!让我们想象我们有一个 ID 为 articles 的集合,我们可以使用 Offset 或 Cursor 分页从这个集合中获取文档:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
首先,我们引入 Appwrite SDK 库并设置一个连接到特定 Appwrite 实例和特定项目的实例。然后,我们使用 Offset 分页列出 10 个文档,同时使用过滤器仅显示已发布的文档。紧接着,我们编写完全相同的列出文档查询,但这次使用 cursor 而不是 offset 分页。
📊 基准测试
我们在这篇文章中经常使用性能这个词,却没有提供任何实际数字,所以让我们一起建立一个基准测试!我们将使用 Appwrite 作为我们的后端服务器,因为它同时支持 Offset 和 Cursor 分页,并使用 Node.JS 编写基准测试脚本。毕竟,Javascript 非常容易上手。
你可以在 GitHub repository 找到完整的源代码。
首先,我们设置 Appwrite,注册一个用户,创建一个项目并创建一个名为 posts 的集合,集合级别权限和读取权限设置为 role:all。要了解更多关于此过程的信息,请访问 Appwrite 文档。我们现在应该已经准备好使用 Appwrite 了。
我们还不能做基准测试,因为我们的数据库是空的!让我们在表中填入一些数据。我们使用以下脚本将数据加载到我们的 MariadDB 数据库中并为基准测试做准备。
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
我们使用了两层 for 循环来提高脚本的速度。第一个 for 循环创建需要等待的查询执行,第二个循环创建一个包含多个插入请求的长查询。理想情况下,我们希望所有内容都在一个请求中,但由于 MySQL 配置的原因,这是不可能的,所以我们将它分成 100 个请求。
我们在不到一分钟的时间内插入了 100 万份文档,我们准备好开始我们的基准测试了。我们将使用 k6 负载测试库进行此演示。
让我们首先对众所周知且广泛使用的 Offset 分页 进行基准测试。在每个测试场景中,我们尝试从数据集的不同部分 获取包含 10 个文档的页面。我们将从 offset 0 开始,一直到 offset 900k,每次增加 100k。基准测试的编写方式是,它一次只发出一个请求,以保持尽可能准确。我们还将运行相同的基准测试十次并测量平均响应时间以确保统计显著性。我们将使用 k6 的 HTTP 客户端向 Appwrite 的 REST API 发出请求。
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
为了使用不同的 offset 配置运行基准测试并将输出存储在 CSV 文件中,我建立了一个简单的 bash 脚本。此脚本执行 k6 十次,每次使用不同的 offset 配置。输出将作为控制台输出提供。
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
在一分钟内,所有基准测试都已完成,并为我提供了每个 offset 配置的 平均响应时间。结果如预期,但一点也不令人满意。
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
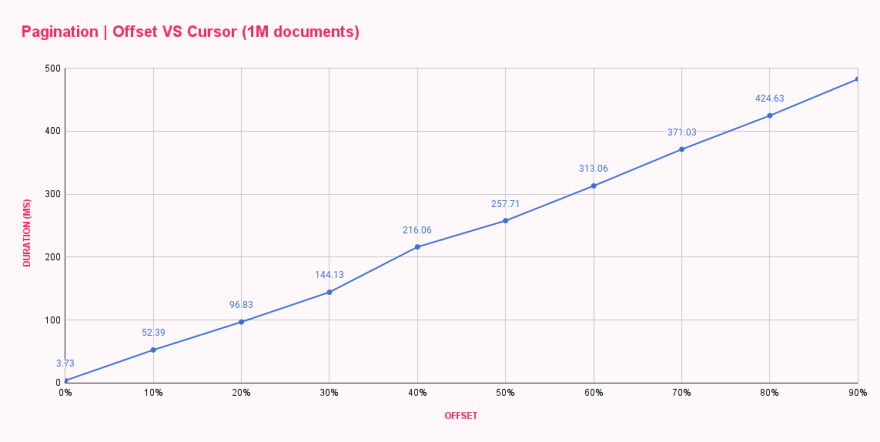
正如我们所见,offset 0 非常快,响应时间不到 4ms。我们的第一个跳转是到 offset 100k,变化非常剧烈,响应时间增加到 52ms。随着 offset 的每次增加,持续时间都在上升,导致在 offset 900k 个文档后获取十个文档几乎需要 500ms。这太疯狂了!
现在让我们更新我们的脚本以使用 Cursor 分页。我们将更新我们的脚本以使用 cursor 而不是 offset,并更新我们的 bash 脚本以提供 cursor(文档 ID)而不是 offset 数字。
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
运行脚本后,我们可以说已经有了性能提升,因为响应时间有明显的差异。我们将结果放入表格中,以并排比较这两种方法。
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
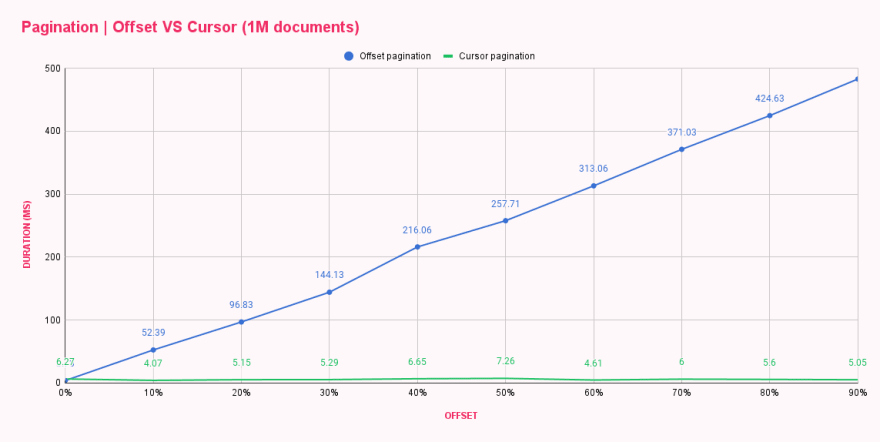
哇!Cursor 分页 太棒了!图表显示 Cursor 分页 不在乎 offset 大小,每个查询都与第一个或最后一个查询一样高效。你能想象重复加载一个巨大列表的最后一页会造成多大的伤害吗? 😬
如果你有兴趣在自己的机器上运行测试,你可以在 GitHub repository 找到完整的源代码。该存储库包含解释整个安装和运行脚本过程的 README.md。
👨🎓 总结
Offset 分页 提供了一种众所周知的分页方法,你可以看到页码并点击它们。这种直观的方法伴随着一堆缺点,例如 高 offsets 时的可怕性能 以及 数据重复 和 数据丢失 的机会。
Cursor 分页 解决了所有这些问题,并带来了一个可靠的分页系统,该系统快速且可以处理 实时(经常变化)数据。Cursor 分页的缺点是 不显示 页码,实现起来很复杂,以及需要克服的一组新挑战,例如丢失 cursor ID。
现在让我们回到我们最初的问题,为什么 GitHub 使用 Cursor 分页,但 Amazon 决定使用 Offset 分页?性能并不总是关键… 用户体验比你的企业必须支付多少服务器费用更有价值。
我相信 Amazon 决定使用 offset 是因为它 改善了 UX,但这也是另一个研究主题。我们已经可以注意到,如果我们访问 amazon.com 并搜索笔,它说这完全有 10 000 个结果,但你只能访问前七页(350 个结果)。
首先,结果远远超过 10k,但 Amazon 限制了它。其次,无论如何你都可以访问前七页。如果你试图访问第 8 页,它会显示 404 错误。正如我们所见,Amazon 意识到了 Offset 分页的性能,但仍然决定保留它,因为他们的用户群偏好查看页码。他们不得不 包含一些限制,但是谁会去搜索结果的第 100 页呢? 🤷
你知道比阅读关于分页的文章更好的是什么吗?试试看!我鼓励你尝试这两种方法,因为最好获得第一手经验。设置 Appwrite 不需要几分钟,你就可以开始玩这两种分页方法了。如果你有任何问题,你也可以在我们的 Discord 服务器上联系我们。