
Photo by Tobias Fischer on Unsplash
👋 Giới thiệu
Cơ sở dữ liệu là một trong những nền tảng của mọi ứng dụng. Đó là nơi bạn lưu trữ mọi thứ mà ứng dụng của bạn cần ghi nhớ, tính toán sau này hoặc hiển thị cho những người dùng trực tuyến khác. Mọi thứ đều vui vẻ cho đến khi cơ sở dữ liệu phát triển và ứng dụng của bạn bắt đầu bị lag vì bạn đang cố gắng tải và hiển thị 1.000 bài đăng cùng một lúc. Chà, bạn là một kỹ sư thông minh phải không? Bạn nhanh chóng vá lỗi đó bằng nút “Xem thêm”. Vài tuần sau, bạn nhận được lỗi Timeout mới! Bạn truy cập Stack Overflow nhưng nhanh chóng nhận ra rằng Ctrl và V đã ngừng hoạt động do sử dụng quá nhiều 🤦 Không còn lựa chọn nào khác, bạn thực sự bắt đầu gỡ lỗi và nhận ra rằng cơ sở dữ liệu trả về hơn 50.000 bài đăng mỗi khi người dùng mở ứng dụng của bạn! Bây giờ chúng ta phải làm gì?

Để ngăn chặn những tình huống khủng khiếp này, chúng ta nên nhận thức được rủi ro ngay từ đầu vì một nhà phát triển có sự chuẩn bị tốt sẽ không bao giờ phải mạo hiểm. Bài viết này sẽ chuẩn bị cho bạn để chống lại các vấn đề hiệu suất liên quan đến cơ sở dữ liệu bằng cách sử dụng offset và cursor pagination.
“Phòng bệnh hơn chữa bệnh.” - Benjamin Franklin
📚 Phân trang là gì?
Phân trang là một chiến lược được sử dụng khi truy vấn bất kỳ tập dữ liệu nào chứa hơn vài trăm bản ghi. Nhờ phân trang, chúng ta có thể chia tập dữ liệu lớn của mình thành các phần (hoặc trang) mà chúng ta có thể tải và hiển thị dần cho người dùng, do đó giảm tải cho cơ sở dữ liệu. Phân trang cũng giải quyết rất nhiều vấn đề về hiệu suất ở cả phía máy khách và máy chủ! Nếu không có phân trang, bạn sẽ phải tải toàn bộ lịch sử trò chuyện chỉ để đọc tin nhắn mới nhất được gửi cho bạn.
Ngày nay, phân trang gần như đã trở thành một điều cần thiết vì mọi ứng dụng đều có khả năng xử lý lượng dữ liệu lớn. Dữ liệu này có thể là bất cứ thứ gì từ nội dung do người dùng tạo, nội dung do quản trị viên hoặc biên tập viên thêm vào, hoặc nhật ký kiểm tra và logs được tạo tự động. Ngay khi danh sách của bạn tăng lên hơn vài nghìn mục, cơ sở dữ liệu của bạn sẽ mất quá nhiều thời gian để giải quyết từng yêu cầu và tốc độ cũng như khả năng truy cập của front-end sẽ bị ảnh hưởng. Đối với người dùng của bạn, trải nghiệm của họ sẽ trông giống như thế này.

Bây giờ chúng ta đã biết phân trang là gì, chúng ta thực sự sử dụng nó như thế nào? Và tại sao nó lại cần thiết?
🔍 Các loại phân trang
Có hai chiến lược phân trang được sử dụng rộng rãi - offset và cursor. Trước khi tìm hiểu sâu và biết mọi thứ về chúng, hãy xem một số trang web đang sử dụng chúng.
Đầu tiên, hãy truy cập trang Stargazer của GitHub và nhận thấy cách tab hiển thị 5,000+ chứ không phải một con số tuyệt đối? Ngoài ra, thay vì số trang tiêu chuẩn, họ sử dụng các nút Previous (Trước) và Next (Tiếp theo).

Bây giờ, hãy chuyển sang danh sách sản phẩm của Amazon và nhận thấy số lượng kết quả chính xác là 364 và phân trang tiêu chuẩn với tất cả các số trang mà bạn có thể nhấp qua 1 2 3 … 20.

Rõ ràng là hai gã khổng lồ công nghệ không thể đồng ý xem giải pháp nào tốt hơn! Tại sao? Chà, chúng ta sẽ cần sử dụng câu trả lời mà các nhà phát triển ghét, Bởi vì nó còn tùy. Hãy khám phá cả hai phương pháp để hiểu ưu điểm, hạn chế và tác động hiệu suất của chúng.
Offset pagination (Phân trang Offset)
Hầu hết các trang web sử dụng phân trang offset vì sự đơn giản và mức độ trực quan của phân trang đối với người dùng. Để triển khai phân trang offset, chúng ta thường cần hai thông tin:
limit- Số hàng cần lấy từ cơ sở dữ liệuoffset- Số hàng cần bỏ qua. Offset giống như số trang, nhưng có một chút toán học xung quanh nó(offset = (page-1) * limit)
Để lấy trang dữ liệu đầu tiên, chúng ta đặt limit thành 10 (vì chúng ta muốn 10 mục trên trang) và offset thành 0 (vì chúng ta muốn bắt đầu đếm 10 mục từ mục thứ 0). Kết quả là, chúng ta sẽ nhận được mười hàng.
Để lấy trang thứ hai, chúng ta giữ limit ở mức 10 (điều này không thay đổi vì chúng ta muốn mỗi trang chứa 10 hàng) và đặt offset thành 10 (trả về kết quả từ hàng thứ 10 trở đi). Chúng ta tiếp tục cách tiếp cận này, do đó cho phép người dùng cuối phân trang qua các kết quả và xem tất cả nội dung của họ.
Trong thế giới SQL, một truy vấn như vậy sẽ được viết là SELECT * FROM posts OFFSET 10 LIMIT 10.
Một số trang web triển khai phân trang offset cũng hiển thị số trang của trang cuối cùng. Họ làm điều đó như thế nào? Bên cạnh kết quả cho mỗi trang, họ cũng có xu hướng trả về một thuộc tính sum cho bạn biết tổng cộng có bao nhiêu hàng. Sử dụng limit, sum và một chút toán học, bạn có thể tính toán số trang cuối cùng bằng cách sử dụng lastPage = ceil(sum / limit)
Mặc dù tính năng này thuận tiện cho người dùng, nhưng các nhà phát triển lại gặp khó khăn trong việc mở rộng loại phân trang này. Nhìn vào thuộc tính sum, chúng ta có thể thấy rằng có thể mất khá nhiều thời gian để đếm tất cả các hàng trong cơ sở dữ liệu đến con số chính xác. Thêm vào đó, offset trong cơ sở dữ liệu được triển khai theo cách lặp qua các hàng để biết cần bỏ qua bao nhiêu hàng. Điều đó có nghĩa là offset của chúng ta càng cao, truy vấn cơ sở dữ liệu của chúng ta sẽ càng mất nhiều thời gian.
Một nhược điểm khác của phân trang offset là nó KHÔNG hoạt động tốt với dữ liệu thời gian thực hoặc dữ liệu thay đổi thường xuyên. Offset cho biết chúng ta muốn bỏ qua bao nhiêu hàng nhưng KHÔNG tính đến việc xóa hàng hoặc tạo hàng mới. Offset như vậy có thể dẫn đến việc hiển thị dữ liệu trùng lặp hoặc một số dữ liệu bị thiếu.
Cursor pagination (Phân trang Cursor)
Cursor là sự kế thừa của offset, vì chúng giải quyết tất cả các vấn đề mà phân trang offset gặp phải - hiệu suất, dữ liệu bị thiếu và dữ liệu trùng lặp bởi vì nó không dựa vào thứ tự tương đối của các hàng như trong trường hợp phân trang offset. Thay vào đó, nó dựa vào một index được tạo và quản lý bởi cơ sở dữ liệu. Để triển khai phân trang cursor, chúng ta sẽ cần thông tin sau:
limit- Tương tự như trước, số lượng hàng chúng ta muốn hiển thị trên một trangcursor- ID của một phần tử tham chiếu trong danh sách. Đây có thể làmục đầu tiênnếu bạn đang truy vấntrang trướcvàmục cuối cùngnếu truy vấntrang tiếp theo.cursorDirection- Nếu người dùng nhấp vào Next hoặc Previous (sau hoặc trước)
Khi yêu cầu trang đầu tiên, chúng ta không cần cung cấp bất cứ thứ gì, chỉ cần limit 10, cho biết chúng ta muốn lấy bao nhiêu hàng. Kết quả là, chúng ta nhận được mười hàng của mình.
Để lấy trang tiếp theo, chúng ta sử dụng ID của hàng cuối cùng làm cursor và đặt cursorDirection thành after.
Tương tự, nếu chúng ta muốn đi đến trang trước, chúng ta sử dụng ID của hàng đầu tiên làm cursor và đặt direction thành before.
Để so sánh, trong thế giới SQL, chúng ta có thể viết truy vấn của mình là SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC.
Các truy vấn sử dụng cursor thay vì offset có hiệu suất cao hơn vì truy vấn WHERE giúp bỏ qua các hàng không mong muốn, trong khi OFFSET cần lặp lại chúng, dẫn đến việc quét toàn bộ bảng (full-table scan). Việc bỏ qua các hàng bằng cách sử dụng WHERE có thể nhanh hơn nữa nếu bạn thiết lập các index thích hợp trên ID của mình. Index được tạo theo mặc định trong trường hợp khóa chính của bạn.
Không chỉ vậy, bạn không còn cần phải lo lắng về việc các hàng bị chèn hoặc xóa. Nếu bạn đang sử dụng offset là 10, bạn sẽ mong đợi chính xác 10 hàng hiện diện trước trang hiện tại của mình. Nếu điều kiện này không được đáp ứng, truy vấn của bạn sẽ trả về kết quả không nhất quán dẫn đến trùng lặp dữ liệu và thậm chí thiếu hàng. Điều này có thể xảy ra nếu bất kỳ hàng nào phía trước trang hiện tại của bạn bị xóa hoặc hàng mới được thêm vào. Phân trang cursor giải quyết vấn đề này bằng cách sử dụng index của hàng cuối cùng bạn đã lấy và nó biết chính xác nơi bắt đầu tìm kiếm khi bạn yêu cầu thêm.
Không phải tất cả đều là màu hồng. Phân trang cursor thực sự là một vấn đề phức tạp nếu bạn cần tự triển khai nó trên backend. Để triển khai phân trang cursor, bạn sẽ cần các mệnh đề WHERE và ORDER BY trong truy vấn của mình. Ngoài ra, bạn cũng sẽ cần các mệnh đề WHERE để lọc theo các điều kiện yêu cầu của bạn. Điều này có thể trở nên khá phức tạp rất nhanh và bạn có thể kết thúc với một truy vấn lồng nhau khổng lồ. Thêm vào đó, bạn cũng sẽ cần tạo index cho tất cả các cột bạn cần truy vấn.
Tuyệt vời! Chúng ta đã loại bỏ trùng lặp và dữ liệu bị thiếu bằng cách chuyển sang phân trang cursor! Nhưng chúng ta vẫn còn một vấn đề. Vì bạn KHÔNG NÊN để lộ ID số tăng dần cho người dùng (vì lý do bảo mật), bây giờ bạn phải duy trì một phiên bản băm của mỗi ID. Bất cứ khi nào bạn cần truy vấn cơ sở dữ liệu, bạn chuyển đổi ID chuỗi này thành ID số của nó bằng cách xem bảng chứa các cặp này. Điều gì xảy ra nếu hàng này bị thiếu? Điều gì xảy ra nếu bạn nhấp vào nút Next, lấy ID của hàng cuối cùng và yêu cầu trang tiếp theo, nhưng cơ sở dữ liệu không thể tìm thấy ID đó?
Đây thực sự là một điều kiện hiếm gặp và chỉ xảy ra nếu ID của hàng mà bạn sắp sử dụng làm cursor vừa bị xóa. Chúng ta có thể giải quyết vấn đề này bằng cách thử các hàng trước đó hoặc lấy lại dữ liệu của các yêu cầu trước đó để cập nhật hàng cuối cùng bằng ID mới, nhưng tất cả những điều đó mang lại một mức độ phức tạp hoàn toàn mới và nhà phát triển cần hiểu một loạt các khái niệm mới, chẳng hạn như đệ quy và quản lý trạng thái phù hợp. Rất may, các dịch vụ như Appwrite sẽ lo việc đó, vì vậy bạn có thể chỉ cần sử dụng phân trang cursor như một tính năng.
🚀 Phân trang trong Appwrite
Appwrite là một backend-as-a-service mã nguồn mở giúp trừu tượng hóa mọi sự phức tạp liên quan đến việc xây dựng một ứng dụng hiện đại bằng cách cung cấp cho bạn một bộ REST API cho các nhu cầu backend cốt lõi của bạn. Appwrite xử lý xác thực và ủy quyền người dùng, cơ sở dữ liệu, lưu trữ tệp, các hàm đám mây, webhooks và nhiều hơn nữa! Nếu thiếu bất cứ điều gì, bạn có thể mở rộng Appwrite bằng ngôn ngữ backend yêu thích của mình.
Appwrite Database cho phép bạn lưu trữ bất kỳ dữ liệu dựa trên văn bản nào cần được chia sẻ giữa những người dùng của bạn. Cơ sở dữ liệu của Appwrite cho phép bạn tạo nhiều bộ sưu tập (bảng) và lưu trữ nhiều tài liệu (hàng) trong đó. Mỗi bộ sưu tập có cấu hình các thuộc tính (cột) để cung cấp cho tập dữ liệu của bạn một schema phù hợp. Bạn cũng có thể cấu hình index để làm cho các truy vấn tìm kiếm của bạn hiệu quả hơn. Khi đọc dữ liệu của bạn, bạn có thể sử dụng một loạt các truy vấn mạnh mẽ, lọc chúng, sắp xếp chúng, giới hạn số lượng kết quả và phân trang trên chúng. Và tất cả những điều này đều có sẵn ngay lập tức!
Điều làm cho Appwrite Database trở nên tốt hơn nữa là sự hỗ trợ phân trang của Appwrite, vì chúng tôi hỗ trợ cả phân trang offset và cursor! Hãy tưởng tượng chúng ta có bộ sưu tập với ID articles, chúng ta có thể lấy tài liệu từ bộ sưu tập này bằng phân trang offset hoặc cursor:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
Đầu tiên, chúng ta nhập thư viện Appwrite SDK và thiết lập một instance kết nối với instance Appwrite cụ thể và một dự án cụ thể. Sau đó, chúng ta liệt kê 10 tài liệu bằng cách sử dụng phân trang offset trong khi có bộ lọc để chỉ hiển thị những tài liệu đã xuất bản. Ngay sau đó, chúng ta viết cùng một truy vấn liệt kê tài liệu chính xác, nhưng lần này sử dụng phân trang cursor thay vì offset.
📊 Điểm chuẩn (Benchmarks)
Chúng ta đã sử dụng từ hiệu suất khá thường xuyên trong bài viết này mà không cung cấp bất kỳ con số thực tế nào, vì vậy hãy cùng nhau tạo ra một điểm chuẩn! Chúng ta sẽ sử dụng Appwrite làm máy chủ backend của mình vì nó hỗ trợ cả phân trang offset và cursor và Node.JS để viết các tập lệnh điểm chuẩn. Rốt cuộc, Javascript khá dễ theo dõi.
Bạn có thể tìm thấy mã nguồn hoàn chỉnh tại GitHub repository.
Đầu tiên, chúng ta thiết lập Appwrite, đăng ký người dùng, tạo dự án và tạo bộ sưu tập có tên posts với quyền cấp bộ sưu tập và quyền đọc được đặt thành role:all. Để tìm hiểu thêm về quy trình này, hãy truy cập tài liệu Appwrite. Bây giờ chúng ta đã sẵn sàng để sử dụng Appwrite.
Chúng ta chưa thể thực hiện điểm chuẩn vì cơ sở dữ liệu của chúng ta đang trống! Hãy điền vào bảng của chúng ta một số dữ liệu. Chúng ta sử dụng tập lệnh sau để tải dữ liệu vào cơ sở dữ liệu MariadDB của mình và chuẩn bị cho điểm chuẩn.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
Chúng tôi đã sử dụng hai lớp vòng lặp for để tăng tốc độ của tập lệnh. Vòng lặp for đầu tiên tạo ra các thực thi truy vấn cần được chờ đợi, và vòng lặp thứ hai tạo ra một truy vấn dài chứa nhiều yêu cầu chèn. Lý tưởng nhất, chúng tôi muốn mọi thứ trong một yêu cầu, nhưng điều đó là không thể do cấu hình MySQL, vì vậy chúng tôi chia nó thành 100 yêu cầu.
Chúng tôi đã chèn 1 triệu tài liệu trong vòng chưa đầy một phút và chúng tôi đã sẵn sàng để bắt đầu điểm chuẩn của mình. Chúng tôi sẽ sử dụng thư viện kiểm tra tải k6 cho bản demo này.
Hãy đánh giá phân trang offset nổi tiếng và được sử dụng rộng rãi trước. Trong mỗi kịch bản thử nghiệm, chúng tôi cố gắng lấy một trang có 10 tài liệu, từ các phần khác nhau của tập dữ liệu của chúng tôi. Chúng tôi sẽ bắt đầu với offset 0 và đi đến tận offset 900k với mức tăng 100k. Điểm chuẩn được viết theo cách mà nó chỉ thực hiện một yêu cầu tại một thời điểm để giữ cho nó chính xác nhất có thể. Chúng tôi cũng sẽ chạy cùng một điểm chuẩn mười lần và đo thời gian phản hồi trung bình để đảm bảo ý nghĩa thống kê. Chúng tôi sẽ sử dụng ứng dụng khách HTTP của k6 để thực hiện các yêu cầu đến REST API của Appwrite.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
Để chạy điểm chuẩn với các cấu hình offset khác nhau và lưu trữ đầu ra trong các tệp CSV, tôi đã tạo một tập lệnh bash đơn giản. Tập lệnh này thực thi k6 mười lần, với cấu hình offset khác nhau mỗi lần. Đầu ra sẽ được cung cấp dưới dạng đầu ra bảng điều khiển.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
Trong vòng một phút, tất cả các điểm chuẩn đã hoàn thành và cung cấp cho tôi thời gian phản hồi trung bình cho mỗi cấu hình offset. Kết quả đúng như mong đợi nhưng không thỏa đáng chút nào.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
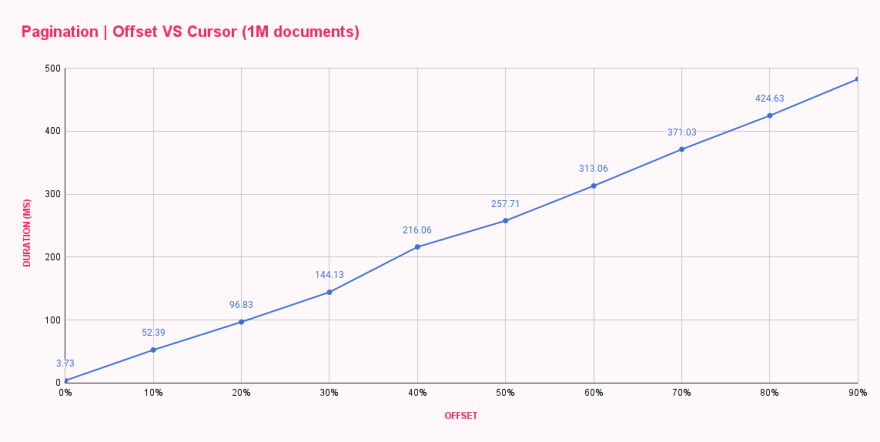
Như chúng ta có thể thấy, offset 0 khá nhanh, phản hồi trong vòng chưa đầy 4ms. Bước nhảy đầu tiên của chúng ta là đến offset 100k, và sự thay đổi rất mạnh mẽ, làm tăng thời gian phản hồi lên 52ms. Với mỗi lần tăng offset, thời gian lại tăng lên, dẫn đến gần 500ms để lấy mười tài liệu sau offset 900k tài liệu. Thật điên rồ!
Bây giờ hãy cập nhật tập lệnh của chúng ta để sử dụng phân trang cursor. Chúng ta sẽ cập nhật tập lệnh của mình để sử dụng cursor thay vì offset và cập nhật tập lệnh bash của chúng tôi để cung cấp cursor (ID tài liệu) thay vì số offset.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
Sau khi chạy tập lệnh, chúng ta đã có thể thấy rằng có một sự tăng cường hiệu suất vì có sự khác biệt rõ rệt về thời gian phản hồi. Chúng tôi đã đưa kết quả vào một bảng để so sánh hai phương pháp phân trang này cạnh nhau.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
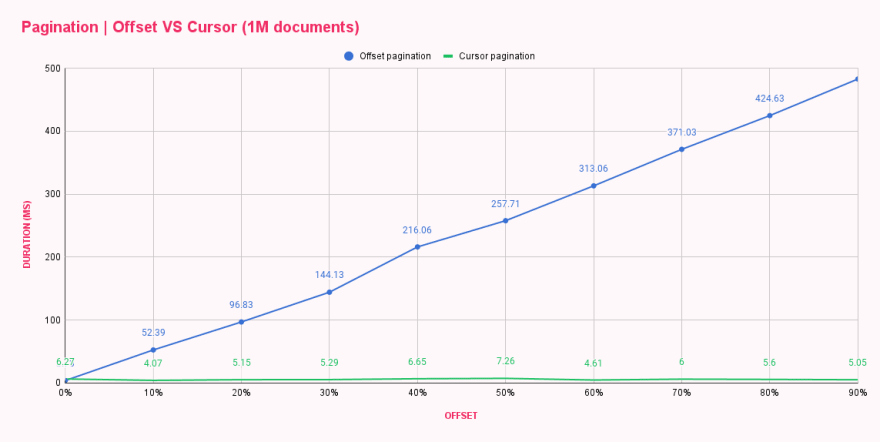
Chà! Phân trang cursor thật tuyệt vời! Biểu đồ cho thấy phân trang cursor KHÔNG QUAN TÂM đến kích thước offset, và mỗi truy vấn đều hiệu quả như truy vấn đầu tiên hoặc cuối cùng. Bạn có thể tưởng tượng được việc tải trang cuối cùng của một danh sách khổng lồ liên tục có thể gây ra bao nhiêu tác hại không? 😬
Nếu bạn quan tâm đến việc chạy thử nghiệm trên máy của riêng mình, bạn có thể tìm thấy mã nguồn hoàn chỉnh dưới dạng kho lưu trữ GitHub. Kho lưu trữ bao gồm README.md giải thích toàn bộ quá trình cài đặt và chạy các tập lệnh.
👨🎓 Tóm tắt
Phân trang offset cung cấp một phương pháp phân trang nổi tiếng, nơi bạn có thể thấy số trang và nhấp qua chúng. Phương pháp trực quan này đi kèm với một loạt các nhược điểm, chẳng hạn như hiệu suất khủng khiếp với offset cao và khả năng trùng lặp dữ liệu và dữ liệu bị thiếu.
Phân trang cursor giải quyết tất cả các vấn đề này và mang lại một hệ thống phân trang đáng tin cậy, nhanh chóng và có thể xử lý dữ liệu thời gian thực (thường xuyên thay đổi). Nhược điểm của phân trang cursor là KHÔNG HIỂN THỊ số trang, độ phức tạp khi triển khai và một loạt các thách thức mới cần vượt qua, chẳng hạn như thiếu ID cursor.
Bây giờ hãy quay lại câu hỏi ban đầu của chúng ta, tại sao GitHub sử dụng phân trang cursor, nhưng Amazon lại quyết định sử dụng phân trang offset? Hiệu suất không phải lúc nào cũng là chìa khóa… Trải nghiệm người dùng có giá trị hơn nhiều so với việc doanh nghiệp của bạn phải trả bao nhiêu tiền cho máy chủ.
Tôi tin rằng Amazon quyết định sử dụng offset vì nó cải thiện UX, nhưng đó là một chủ đề cho một nghiên cứu khác. Chúng ta đã có thể nhận thấy rằng nếu chúng ta truy cập amazon.com và tìm kiếm một chiếc bút, nó nói rằng có chính xác 10 000 kết quả, nhưng bạn chỉ có thể truy cập bảy trang đầu tiên (350 kết quả).
Đầu tiên, có nhiều hơn 10k kết quả, nhưng Amazon giới hạn nó. Thứ hai, dù sao thì bạn cũng có thể truy cập bảy trang đầu tiên. Nếu bạn cố gắng truy cập trang 8, nó sẽ hiển thị lỗi 404. Như chúng ta có thể thấy, Amazon nhận thức được hiệu suất của phân trang offset nhưng vẫn quyết định giữ nó vì cơ sở người dùng của họ thích xem số trang. Họ đã phải đưa vào một số giới hạn, nhưng ai sẽ đi đến trang 100 của kết quả tìm kiếm chứ? 🤷
Bạn có biết điều gì tốt hơn là đọc về phân trang không? Hãy thử nó! Tôi khuyến khích bạn thử cả hai phương pháp vì tốt nhất là có kinh nghiệm trực tiếp. Thiết lập Appwrite mất chưa đầy vài phút và bạn có thể bắt đầu chơi với cả hai phương pháp phân trang. Nếu bạn có bất kỳ câu hỏi nào, bạn cũng có thể liên hệ với chúng tôi trên máy chủ Discord của chúng tôi.