
Photo by Tobias Fischer on Unsplash
👋 บทนำ
ฐานข้อมูล (Database) เปรียบเสมือนรากฐานสำคัญของทุกแอปพลิเคชัน เป็นที่ที่คุณเก็บทุกอย่างที่แอปต้องจดจำ คำนวณในภายหลัง หรือแสดงให้ผู้ใช้ออนไลน์คนอื่นๆ เห็น ทุกอย่างดูสนุกสนานจนกระทั่งฐานข้อมูลเริ่มใหญ่ขึ้นและแอปพลิเคชันของคุณเริ่มกระตุกเพราะคุณพยายามดึงข้อมูลและเรนเดอร์โพสต์ 1,000 รายการพร้อมกัน เอาล่ะ คุณเป็นวิศวกรที่ฉลาดใช่ไหม? คุณรีบแก้ปัญหานั้นด้วยปุ่ม “แสดงเพิ่มเติม” ไม่กี่สัปดาห์ต่อมา คุณก็พบกับข้อผิดพลาด Timeout ใหม่! คุณมุ่งหน้าไปที่ Stack Overflow แต่ก็รู้ตัวอย่างรวดเร็วว่า Ctrl และ V หยุดทำงานเนื่องจากการใช้งานที่มากเกินไป 🤦 เมื่อไม่มีทางเลือกอื่น คุณจึงเริ่มดีบักและพบว่าฐานข้อมูลส่งคืนโพสต์มากกว่า 50,000 รายการทุกครั้งที่ผู้ใช้เปิดแอปของคุณ! แล้วเราจะทำอย่างไรดี?

เพื่อป้องกันสถานการณ์อันน่าสยดสยองเหล่านี้ เราควรตระหนักถึงความเสี่ยงตั้งแต่เริ่มต้น เพราะนักพัฒนาที่เตรียมพร้อมอย่างดีจะไม่ต้องเสี่ยง บทความนี้จะเตรียมคุณให้พร้อมรับมือกับปัญหาประสิทธิภาพที่เกี่ยวข้องกับฐานข้อมูลโดยใช้ offset และ cursor pagination
“การป้องกันไว้ก่อนดีกว่าแก้” - เบนจามิน แฟรงคลิน
📚 การแบ่งหน้า (Pagination) คืออะไร?
การแบ่งหน้า หรือ Pagination เป็นกลยุทธ์ที่ใช้เมื่อ สอบถามชุดข้อมูลที่มีระเบียน (records) มากกว่าสองสามร้อยรายการ ต้องขอบคุณการแบ่งหน้า เราสามารถแบ่ง ชุดข้อมูลขนาดใหญ่ ออกเป็น ส่วนๆ (หรือหน้า) ที่เราสามารถทยอยดึงข้อมูลและแสดงผลให้ผู้ใช้เห็น ซึ่งจะช่วย ลดภาระของฐานข้อมูล การแบ่งหน้ายังช่วยแก้ปัญหาประสิทธิภาพมากมายทั้งฝั่งไคลเอนต์และเซิร์ฟเวอร์! หากไม่มีการแบ่งหน้า คุณจะต้องโหลดประวัติการแชททั้งหมดเพียงเพื่ออ่านข้อความล่าสุดที่ส่งถึงคุณ
ทุกวันนี้ การแบ่งหน้าแทบจะกลายเป็นสิ่งจำเป็น เนื่องจากทุกแอปพลิเคชันมีแนวโน้มที่จะจัดการกับ ข้อมูลจำนวนมาก ข้อมูลนี้อาจเป็นอะไรก็ได้ตั้งแต่เนื้อหาที่ผู้ใช้สร้างขึ้น เนื้อหาที่เพิ่มโดยผู้ดูแลระบบหรือบรรณาธิการ หรือบันทึกการตรวจสอบและ log ที่สร้างขึ้นโดยอัตโนมัติ ทันทีที่รายการของคุณเพิ่มขึ้นเกินสองสามพันรายการ ฐานข้อมูลของคุณใช้เวลานานเกินไปในการจัดการแต่ละคำขอ และความเร็วและการเข้าถึงของส่วนหน้า (front-end) จะได้รับผลกระทบ สำหรับผู้ใช้ของคุณ ประสบการณ์ของพวกเขาจะดูเหมือนสิ่งนี้

ตอนนี้เรารู้แล้วว่าการแบ่งหน้าคืออะไร เราจะใช้งานมันอย่างไร? และทำไมมันถึงจำเป็น?
🔍 ประเภทของการแบ่งหน้า
มีกลยุทธ์การแบ่งหน้าที่ใช้กันอย่างแพร่หลายสองแบบ คือ offset และ cursor ก่อนที่จะเจาะลึกและเรียนรู้ทุกอย่างเกี่ยวกับพวกมัน ลองดูเว็บไซต์บางแห่งที่ใช้พวกมันกัน
อันดับแรก ลองไปที่หน้า Stargazer ของ GitHub และสังเกตว่าแท็บระบุว่า 5,000+ แทนที่จะเป็นตัวเลขที่แน่นอนหรือไม่? นอกจากนี้ แทนที่จะเป็น หมายเลขหน้าตามมาตรฐาน พวกเขาใช้ปุ่ม Previous (ก่อนหน้า) และ Next (ถัดไป)

ตอนนี้ ลองเปลี่ยนไปที่รายการสินค้าของ Amazon และสังเกตจำนวนผลลัพธ์ที่แน่นอน 364 รายการ และ การแบ่งหน้าแบบมาตรฐาน ที่มี หมายเลขหน้าทั้งหมด ที่คุณสามารถคลิกผ่าน 1 2 3 … 20 ได้

เห็นได้ชัดว่ายักษ์ใหญ่ด้านเทคโนโลยีสองรายไม่สามารถตกลงกันได้ว่าวิธีแก้ปัญหาใดดีกว่า! ทำไมล่ะ? เอาล่ะ เราต้องใช้คำตอบที่นักพัฒนาเกลียด นั่นคือ “มันขึ้นอยู่กับสถานการณ์” มาสำรวจทั้งสองวิธีเพื่อทำความเข้าใจข้อดี ข้อจำกัด และผลกระทบต่อประสิทธิภาพกัน
Offset pagination
เว็บไซต์ส่วนใหญ่ใช้ Offset pagination เนื่องจาก ความเรียบง่าย และความ ใช้งานง่าย ของการแบ่งหน้าสำหรับผู้ใช้ ในการใช้ Offset pagination เรามักจะต้องใช้ข้อมูลสองส่วน:
limit- จำนวนแถวที่จะ ดึงข้อมูลจากฐานข้อมูลoffset- จำนวน แถวที่จะข้าม Offset เหมือนกับหมายเลขหน้า แต่มีคณิตศาสตร์เข้ามาเกี่ยวข้องนิดหน่อย(offset = (page-1) * limit)
ในการรับหน้าแรกของข้อมูล เราตั้งค่า limit เป็น 10 (เพราะเราต้องการ 10 รายการในหน้า) และ offset เป็น 0 (เพราะเราต้องการเริ่มนับ 10 รายการตั้งแต่รายการที่ 0) ผลลัพธ์คือเราจะได้สิบแถว
ในการรับหน้าที่สอง เราคง limit ไว้ที่ 10 (ไม่เปลี่ยนแปลงเพราะเราต้องการให้ทุกหน้ามี 10 แถว) และตั้งค่า offset เป็น 10 (ส่งคืนผลลัพธ์ตั้งแต่แถวที่ 10 เป็นต้นไป) เราดำเนินการตามแนวทางนี้ต่อไปเพื่อให้ผู้ใช้ปลายทางสามารถแบ่งหน้าผ่านผลลัพธ์และดูเนื้อหาทั้งหมดของพวกเขาได้
ในโลกของ SQL คำสั่งดังกล่าวจะเขียนว่า SELECT * FROM posts OFFSET 10 LIMIT 10
เว็บไซต์บางแห่งที่ใช้ Offset pagination ยังแสดงหมายเลขหน้าของหน้าสุดท้ายด้วย พวกเขาทำได้อย่างไร? นอกเหนือจากผลลัพธ์สำหรับแต่ละหน้าแล้ว พวกเขามักจะส่งคืนคุณลักษณะ sum ที่บอกคุณว่ามีแถวทั้งหมดกี่แถว ด้วย limit, sum และคณิตศาสตร์นิดหน่อย คุณสามารถคำนวณหมายเลขหน้าสุดท้ายโดยใช้ lastPage = ceil(sum / limit)
แม้ว่าคุณสมบัตินี้จะสะดวกสำหรับผู้ใช้ แต่นักพัฒนาก็ต้องดิ้นรนเพื่อขยายขนาดการแบ่งหน้าประเภทนี้ เมื่อดูที่คุณลักษณะ sum เราจะเห็นได้ว่าการนับแถวทั้งหมดในฐานข้อมูลให้ได้ตัวเลขที่แน่นอนอาจใช้เวลาค่อนข้างนาน นอกจากนั้น offset ในฐานข้อมูลยังถูกนำไปใช้ในลักษณะที่ วนซ้ำผ่านแถวต่างๆ เพื่อให้รู้ว่าควรข้ามไปกี่แถว นั่นหมายความว่า ยิ่ง offset ของเราสูงเท่าไหร่ การสืบค้นฐานข้อมูลของเราก็จะยิ่งใช้เวลานานขึ้นเท่านั้น
ข้อเสียอีกประการของ Offset pagination คือมัน ไม่ เหมาะกับ ข้อมูลเรียลไทม์ หรือ ข้อมูลที่เปลี่ยนแปลงบ่อย Offset บอกว่า เราต้องการข้ามไปกี่แถว แต่ ไม่ได้ คำนึงถึง การลบแถว หรือ การสร้างแถว ใหม่ offset ดังกล่าวอาจส่งผลให้แสดง ข้อมูลซ้ำ หรือ ข้อมูลหายไป บางส่วน
Cursor pagination
Cursor เป็นผู้สืบทอดของ offset เนื่องจากพวกมันแก้ปัญหาทั้งหมดที่ Offset pagination มี ไม่ว่าจะเป็น ประสิทธิภาพ, ข้อมูลที่หายไป และ ข้อมูลซ้ำซ้อน เนื่องจากมันไม่ได้ขึ้นอยู่กับ ลำดับสัมพัทธ์ของแถว เหมือนในกรณีของ Offset pagination แต่จะขึ้นอยู่กับ ดัชนี (index) ที่สร้างขึ้น และจัดการโดยฐานข้อมูล ในการใช้ Cursor pagination เราจะต้องใช้ข้อมูลต่อไปนี้:
limit- เหมือนเดิม จำนวนแถวที่เราต้องการแสดงในหน้าเดียวcursor- ID ของ องค์ประกอบอ้างอิง ในรายการ นี่อาจเป็นรายการแรกหากคุณกำลังสืบค้นหน้าก่อนหน้าและรายการสุดท้ายหากสืบค้นหน้าถัดไปcursorDirection- หากผู้ใช้คลิก Next หรือ Previous (หลังจาก หรือ ก่อนหน้า)
เมื่อร้องขอ หน้าแรก เราไม่จำเป็นต้องระบุอะไรเลย เพียงแค่ limit 10 เพื่อบอกว่าเราต้องการกี่แถว ผลลัพธ์คือเราได้สิบแถวของเรา
ในการรับหน้าถัดไป เราใช้ ID ของ แถวสุดท้าย เป็น cursor และตั้งค่า cursorDirection เป็น after
ในทำนองเดียวกัน หากเราต้องการไปที่ หน้าก่อนหน้า เราจะใช้ ID ของ แถวแรก เป็น cursor และตั้งค่า direction เป็น before
เพื่อเปรียบเทียบ ในโลกของ SQL เราสามารถเขียนคำสั่งของเราได้ว่า SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC
การสืบค้นที่ใช้ cursor แทน offset มีประสิทธิภาพมากกว่าเพราะคำสั่ง WHERE ช่วย ข้ามแถวที่ไม่ต้องการ ในขณะที่ OFFSET จำเป็นต้อง วนซ้ำ (iterate) ผ่านพวกมัน ส่งผลให้เกิดการ full-table scan (สแกนทั้งตาราง) การข้ามแถวโดยใช้ WHERE จะ เร็วยิ่งขึ้น หากคุณตั้งค่าดัชนีที่เหมาะสมบน ID ของคุณ ดัชนีจะถูกสร้างขึ้นโดยค่าเริ่มต้นในกรณีของ primary key ของคุณ
ไม่เพียงเท่านั้น คุณ ไม่ต้องกังวลอีกต่อไป เกี่ยวกับแถวที่ถูก แทรก หรือ ลบ หากคุณใช้ offset 10 คุณจะคาดหวังว่าจะมี 10 แถวพอดิบพอดีอยู่ข้างหน้าหน้าปัจจุบันของคุณ หากเงื่อนไขนี้ไม่เป็นจริง คำสั่งของคุณจะส่งคืน ผลลัพธ์ที่ไม่สอดคล้อง ซึ่งนำไปสู่ ข้อมูลซ้ำซ้อน หรือแม้แต่ แถวที่หายไป สิ่งนี้สามารถเกิดขึ้นได้หากแถวใดๆ ข้างหน้าหน้าปัจจุบันของคุณ ถูก ลบ หรือ มีการเพิ่มแถวใหม่ Cursor pagination แก้ปัญหานี้โดยใช้ ดัชนีของแถวสุดท้าย ที่คุณดึงมา และมันรู้ อย่างแน่ชัดว่าควรเริ่มค้นหาจากที่ใดเมื่อคุณร้องขอเพิ่มเติม
มันไม่ได้สวยหรูไปซะหมด Cursor pagination เป็นปัญหาที่ซับซ้อนจริงๆ หากคุณต้องนำไปใช้บนแบ็กเอนด์ด้วยตัวเอง ในการใช้ Cursor pagination คุณจะต้องมีคำสั่ง WHERE และ ORDER BY ในการสืบค้นของคุณ นอกจากนี้ คุณยังต้องมีคำสั่ง WHERE เพื่อกรองตามเงื่อนไขที่คุณต้องการ สิ่งนี้อาจซับซ้อนได้อย่างรวดเร็วและคุณอาจลงเอยด้วยการสืบค้นที่ซ้อนกันขนาดใหญ่ นอกจากนั้น คุณยังต้องสร้างดัชนีสำหรับคอลัมน์ทั้งหมดที่คุณต้องการสืบค้นด้วย
เยี่ยมมาก! เรากำจัด ข้อมูลซ้ำซ้อน และ ข้อมูลที่หายไป โดยเปลี่ยนไปใช้ Cursor pagination! แต่เรายังเหลือปัญหาอีกหนึ่งอย่าง เนื่องจากคุณ ไม่ควร เปิดเผย ID ที่เป็นตัวเลขเรียงลำดับ ให้ผู้ใช้เห็น (ด้วยเหตุผลด้านความปลอดภัย) ตอนนี้คุณต้องรักษา เวอร์ชันแฮช (hashed version) ของแต่ละ ID เมื่อใดก็ตามที่คุณต้องการสืบค้นฐานข้อมูล คุณจะแปลง string ID นี้เป็น numeric ID โดยดูที่ตารางที่เก็บคู่เหล่านี้ไว้ จะเกิดอะไรขึ้นถ้า แถวนี้หายไป? จะเกิดอะไรขึ้นถ้าคุณคลิกปุ่ม Next เอา ID ของแถวสุดท้าย แล้วร้องขอหน้าถัดไป แต่ฐานข้อมูลหา ID นั้นไม่เจอ?
นี่เป็นเงื่อนไขที่หายากจริงๆ และเกิดขึ้นก็ต่อเมื่อ ID ของแถวที่คุณกำลังจะใช้เป็น cursor เพิ่งถูกลบไป เราสามารถแก้ปัญหานี้ได้โดย ลองแถวก่อนหน้า หรือ ดึงข้อมูลของคำขอก่อนหน้านี้ใหม่ เพื่ออัปเดตแถวสุดท้ายด้วย ID ใหม่ แต่ทั้งหมดนั้นนำมาซึ่งความซับซ้อนระดับใหม่ และนักพัฒนาจำเป็นต้องเข้าใจแนวคิดใหม่ๆ มากมาย เช่น recursion และ การจัดการ state ที่เหมาะสม โชคดีที่บริการต่างๆ เช่น Appwrite ดูแลเรื่องนั้นให้ คุณจึงสามารถใช้ Cursor pagination เป็นฟีเจอร์ได้อย่างง่ายดาย
🚀 การแบ่งหน้าใน Appwrite
Appwrite เป็น backend-as-a-service แบบโอเพ่นซอร์สที่รวบรวมความซับซ้อนทั้งหมดที่เกี่ยวข้องกับการสร้างแอปพลิเคชันสมัยใหม่ โดยมอบชุด REST API สำหรับความต้องการหลักของแบ็กเอนด์ให้กับคุณ Appwrite จัดการการตรวจสอบและยืนยันตัวตนผู้ใช้, ฐานข้อมูล, การจัดเก็บไฟล์, ฟังก์ชันคลาวด์, webhooks และอื่นๆ อีกมากมาย! หากมีอะไรขาดหายไป คุณสามารถขยาย Appwrite โดยใช้ภาษาแบ็กเอนด์ที่คุณชื่นชอบได้
Appwrite Database ให้คุณจัดเก็บข้อมูลแบบข้อความที่ต้องแชร์กับผู้ใช้ของคุณ ฐานข้อมูลของ Appwrite ช่วยให้คุณสร้างหลายคอลเล็กชัน (ตาราง) และจัดเก็บเอกสารหลายฉบับ (แถว) ไว้ในนั้น แต่ละคอลเล็กชันมีคุณลักษณะ (คอลัมน์) ที่กำหนดค่าไว้เพื่อให้ข้อมูลของคุณมี schema ที่เหมาะสม คุณยังสามารถกำหนดค่าดัชนีเพื่อให้คำสั่งค้นหาของคุณมีประสิทธิภาพมากขึ้น เมื่ออ่านข้อมูลของคุณ คุณสามารถใช้คำสั่งที่มีประสิทธิภาพมากมาย กรอง เรียงลำดับ จำกัดจำนวนผลลัพธ์ และแบ่งหน้า และทั้งหมดนี้มาพร้อมให้ใช้งานได้ทันที!
สิ่งที่ทำให้ Appwrite Database ดียิ่งขึ้นไปอีกคือการรองรับการแบ่งหน้าของ Appwrite เนื่องจากเรารองรับทั้ง Offset และ Cursor pagination! ลองจินตนาการว่าเรามีคอลเล็กชันที่มี ID articles เราสามารถรับเอกสารจากคอลเล็กชันนี้ด้วย Offset หรือ Cursor pagination:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
ขั้นแรก เรานำเข้าไลบรารี Appwrite SDK และตั้งค่าอินสแตนซ์ที่เชื่อมต่อกับอินสแตนซ์ Appwrite เฉพาะและโปรเจกต์เฉพาะ จากนั้น เราแสดงรายชื่อเอกสาร 10 ฉบับโดยใช้ Offset pagination ในขณะที่มีตัวกรองเพื่อแสดงเฉพาะเอกสารที่เผยแพร่แล้ว หลังจากนั้นทันที เราเขียนคำสั่งแสดงรายชื่อเอกสารที่เหมือนกันทุกประการ แต่ครั้งนี้ใช้ cursor แทน offset pagination
📊 การวัดประสิทธิภาพ (Benchmarks)
เราใช้คำว่าประสิทธิภาพบ่อยมากในบทความนี้โดยไม่ได้ให้ตัวเลขจริงใดๆ ดังนั้นเรามาสร้างการวัดประสิทธิภาพด้วยกันเถอะ! เราจะใช้ Appwrite เป็นเซิร์ฟเวอร์แบ็กเอนด์ของเรา เนื่องจากรองรับทั้ง Offset และ Cursor pagination และใช้ Node.JS เพื่อเขียนสคริปต์วัดผล ท้ายที่สุดแล้ว Javascript ก็ค่อนข้างง่ายที่จะทำตาม
คุณสามารถค้นหาซอร์สโค้ดฉบับสมบูรณ์ได้ที่ GitHub repository
ขั้นแรก เราตั้งค่า Appwrite ลงทะเบียนผู้ใช้ สร้างโปรเจกต์ และสร้างคอลเล็กชันชื่อ posts ที่มีสิทธิ์ระดับคอลเล็กชันและสิทธิ์การอ่านตั้งค่าเป็น role:all หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับกระบวนการนี้ โปรดไปที่เอกสาร Appwrite ตอนนี้เราน่าจะมี Appwrite ที่พร้อมใช้งานแล้ว
เรายังไม่สามารถทำ benchmark ได้ เพราะฐานข้อมูลของเราว่างเปล่า! มาเติมข้อมูลในตารางของเรากันเถอะ เราใช้สคริปต์ต่อไปนี้เพื่อโหลดข้อมูลลงในฐานข้อมูล MariadDB ของเราและเตรียมพร้อมสำหรับการวัดผล
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
เราใช้การวนซ้ำ for loop สองชั้นเพื่อเพิ่มความเร็วของสคริปต์ for loop แรกสร้างการดำเนินการสืบค้นที่ต้องรอ และ loop ที่สองสร้างคำสั่งสืบค้นยาวที่มีคำขอแทรกหลายรายการ ในอุดมคติ เราต้องการให้ทุกอย่างอยู่ในคำขอเดียว แต่เป็นไปไม่ได้เนื่องจากการกำหนดค่า MySQL ดังนั้นเราจึงแบ่งออกเป็น 100 คำขอ
เรามี เอกสาร 1 ล้านฉบับ ถูกแทรกในเวลาไม่ถึงหนึ่งนาที และเราพร้อมที่จะเริ่มการวัดผลของเราแล้ว เราจะใช้ไลบรารีทดสอบโหลด k6 สำหรับการสาธิตนี้
มาวัดผล Offset pagination ที่เป็นที่รู้จักและใช้กันอย่างแพร่หลายกันก่อน ในแต่ละสถานการณ์ทดสอบ เราพยายาม ดึงหน้าที่มีเอกสาร 10 ฉบับ จากส่วนต่างๆ ของชุดข้อมูลของเรา เราจะเริ่มต้นด้วย offset 0 และไปจนถึง offset 900k โดยเพิ่มทีละ 100k การวัดผลเขียนขึ้นในลักษณะที่สร้างคำขอเพียงรายการเดียวในแต่ละครั้งเพื่อให้แม่นยำที่สุด นอกจากนี้เราจะรัน benchmark เดียวกันสิบครั้งและวัดเวลาตอบสนองโดยเฉลี่ยเพื่อให้มั่นใจถึงนัยสำคัญทางสถิติ เราจะใช้ไคลเอนต์ HTTP ของ k6 เพื่อร้องขอไปยัง REST API ของ Appwrite
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
ในการรัน benchmark ด้วยการกำหนดค่า offset ที่แตกต่างกันและจัดเก็บผลลัพธ์ในไฟล์ CSV ผมได้สร้าง bash script ง่ายๆ ขึ้นมา สคริปต์นี้รัน k6 สิบครั้ง โดย แต่ละครั้งมีการกำหนดค่า offset ที่แตกต่างกัน ผลลัพธ์จะแสดงเป็น console output
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
ภายในหนึ่งนาที การวัดผลทั้งหมดก็เสร็จสิ้นและให้ เวลาตอบสนองเฉลี่ย สำหรับการกำหนดค่า offset แต่ละรายการแก่ผม ผลลัพธ์เป็นไปตามคาดแต่ไม่น่าพอใจเลย
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
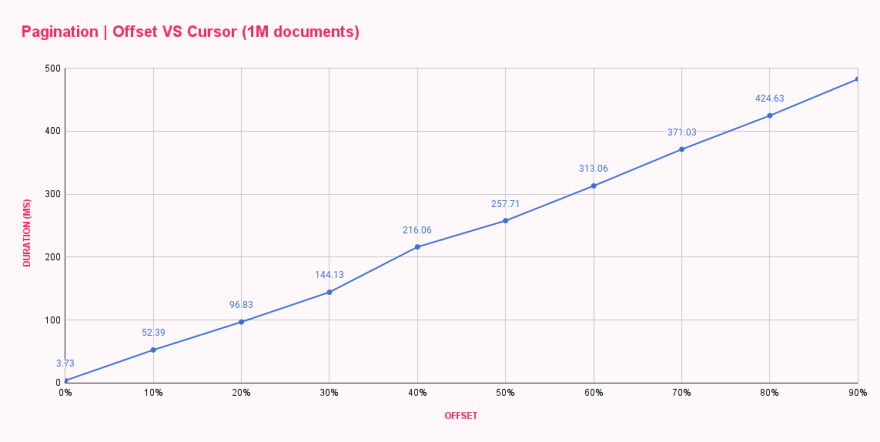
อย่างที่เราเห็น offset 0 ค่อนข้างเร็ว ตอบสนองในเวลาน้อยกว่า 4ms การกระโดดครั้งแรกของเราคือไปที่ offset 100k และการเปลี่ยนแปลงนั้นรุนแรงมาก โดยเพิ่มเวลาตอบสนองเป็น 52ms ในแต่ละครั้งที่เพิ่ม offset ระยะเวลาก็เพิ่มขึ้น ส่งผลให้เกือบ 500ms ในการรับเอกสารสิบฉบับหลังจาก offset 900k เอกสาร นั่นมันบ้ามาก!
ตอนนี้เรามาอัปเดตสคริปต์ของเราเพื่อใช้ Cursor pagination กัน เราจะอัปเดตสคริปต์ของเราเพื่อใช้ cursor แทน offset และอัปเดต bash script ของเราเพื่อให้ cursor (document ID) แทนหมายเลข offset
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
หลังจากรันสคริปต์ เราก็บอกได้แล้วว่ามีการเพิ่มประสิทธิภาพเนื่องจากเวลาตอบสนองมีความแตกต่างอย่างเห็นได้ชัด เราได้ใส่ผลลัพธ์ลงในตารางเพื่อเปรียบเทียบวิธีการแบ่งหน้าทั้งสองนี้แบบเคียงข้างกัน
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
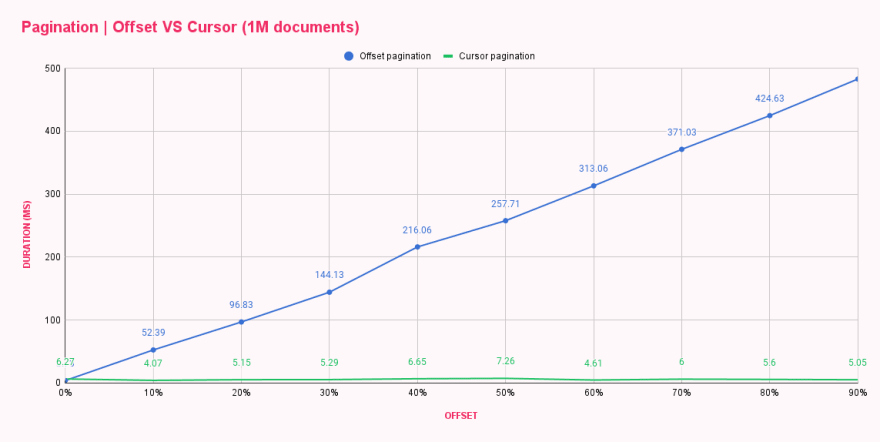
ว้าว! Cursor pagination เจ๋งมาก! กราฟแสดงให้เห็นว่า Cursor pagination ไม่สนใจ ขนาด offset และทุกคำสั่งสืบค้นก็มีประสิทธิภาพพอๆ กับคำสั่งแรกหรือคำสั่งสุดท้าย คุณนึกภาพออกไหมว่าจะเกิดความเสียหายมากแค่ไหนจากการโหลดหน้าสุดท้ายของรายการขนาดใหญ่ซ้ำๆ? 😬
หากคุณสนใจที่จะรันการทดสอบบนเครื่องของคุณเอง คุณสามารถค้นหาซอร์สโค้ดฉบับสมบูรณ์ได้ที่ GitHub repository ที่เก็บข้อมูลประกอบด้วย README.md ที่อธิบายกระบวนการติดตั้งและรันสคริปต์ทั้งหมด
👨🎓 สรุป
Offset pagination นำเสนอวิธีการแบ่งหน้าที่รู้จักกันดีซึ่งคุณสามารถดูหมายเลขหน้าและคลิกผ่านได้ วิธีที่ใช้งานง่ายนี้มาพร้อมกับข้อเสียมากมาย เช่น ประสิทธิภาพที่แย่มากเมื่อมี offset สูง และโอกาสที่จะเกิด ข้อมูลซ้ำซ้อน และ ข้อมูลหายไป
Cursor pagination แก้ปัญหาเหล่านี้ทั้งหมดและนำระบบการแบ่งหน้าที่เชื่อถือได้ซึ่งรวดเร็วและสามารถจัดการ ข้อมูลเรียลไทม์ (ที่เปลี่ยนแปลงบ่อย) ได้ ข้อเสียของ Cursor pagination คือ ไม่แสดง หมายเลขหน้า, ความซับซ้อนในการใช้งาน, และความท้าทายชุดใหม่ที่ต้องเอาชนะ เช่น cursor ID ที่หายไป
ตอนนี้กลับมาที่คำถามเดิมของเรา ทำไม GitHub ถึงใช้ Cursor pagination แต่ Amazon ตัดสินใจใช้ Offset pagination? ประสิทธิภาพไม่ใช่กุญแจสำคัญเสมอไป… ประสบการณ์ของผู้ใช้มีค่ามากกว่าจำนวนเซิร์ฟเวอร์ที่ธุรกิจของคุณต้องจ่าย
ฉันเชื่อว่า Amazon ตัดสินใจใช้ offset เพราะมัน ปรับปรุง UX แต่นั่นเป็นหัวข้อสำหรับการวิจัยอีกเรื่องหนึ่ง เราสังเกตได้ว่าถ้าเราไปที่ amazon.com และค้นหาปากกา มันบอกว่ามีผลลัพธ์ 10,000 รายการพอดี แต่คุณเข้าชมได้แค่ 7 หน้าแรก (350 ผลลัพธ์)
ประการแรก มีผลลัพธ์มากกว่า 10k รายการ แต่ Amazon จำกัดไว้ ประการที่สอง คุณสามารถเข้าชม 7 หน้าแรกได้อยู่ดี หากคุณพยายามไปที่หน้า 8 จะแสดงข้อผิดพลาด 404 อย่างที่เราเห็น Amazon ตระหนักถึง ประสิทธิภาพของ Offset pagination แต่ยังคงตัดสินใจเก็บไว้เพราะฐานผู้ใช้ของพวกเขาชอบเห็นหมายเลขหน้า พวกเขาต้อง รวมข้อจำกัดบางอย่าง แต่ใครจะไปที่หน้า 100 ของผลลัพธ์การค้นหากันล่ะ? 🤷
คุณรู้ไหมว่าอะไรดีกว่าการอ่านเกี่ยวกับการแบ่งหน้า? การลองใช้ไง! ฉันขอแนะนำให้คุณลองทั้งสองวิธีเพราะดีที่สุดที่จะได้รับประสบการณ์โดยตรง การตั้งค่า Appwrite ใช้เวลาไม่ถึงไม่กี่นาที และคุณสามารถเริ่มเล่นกับวิธีการแบ่งหน้าทั้งสองแบบ หากคุณมีคำถามใดๆ คุณสามารถติดต่อเราได้ที่เซิร์ฟเวอร์ Discord ของเรา