
Photo by Tobias Fischer on Unsplash
👋 Введение
База данных — один из краеугольных камней любого приложения. Именно здесь вы храните все, что вашему приложению нужно запомнить, вычислить позже или показать другим пользователям онлайн. Все идет весело и задорно, пока база данных не разрастается, и ваше приложение не начинает тормозить, потому что вы пытались получить и отобразить 1000 постов одновременно. Ну, вы же умный инженер, верно? Вы быстро исправляете это с помощью кнопки «Показать еще». Через несколько недель вы сталкиваетесь с новой ошибкой Timeout! Вы отправляетесь на Stack Overflow, но быстро понимаете, что Ctrl и V перестали работать из-за чрезмерного использования 🤦 Не имея больше вариантов в своем распоряжении, вы действительно начинаете отладку и понимаете, что база данных возвращает более 50 000 постов каждый раз, когда пользователь открывает ваше приложение! Что же нам теперь делать?

Чтобы предотвратить эти ужасные сценарии, мы должны знать о рисках с самого начала, потому что хорошо подготовленному разработчику никогда не придется рисковать. Эта статья подготовит вас к борьбе с проблемами производительности, связанными с базой данных, с использованием offset и cursor pagination.
“Унция профилактики стоит фунта лечения.” - Бенджамин Франклин
📚 Что такое пагинация?
Пагинация — это стратегия, используемая при запросе любого набора данных, содержащего более нескольких сотен записей. Благодаря пагинации мы можем разделить наш большой набор данных на куски (или страницы), которые мы можем постепенно извлекать и отображать пользователю, тем самым снижая нагрузку на базу данных. Пагинация также решает множество проблем с производительностью как на стороне клиента, так и на стороне сервера! Без пагинации вам пришлось бы загружать всю историю чата только для того, чтобы прочитать последнее отправленное вам сообщение.
В наши дни пагинация стала почти необходимостью, так как каждое приложение, скорее всего, будет работать с большими объемами данных. Эти данные могут быть чем угодно: от пользовательского контента, контента, добавленного администраторами или редакторами, до автоматически генерируемых аудитов и логов. Как только ваш список разрастется до более чем нескольких тысяч элементов, вашей базе данных потребуется слишком много времени для разрешения каждого запроса, и скорость и доступность вашего интерфейса пострадают. Что касается ваших пользователей, их опыт будет выглядеть примерно так.

Теперь, когда мы знаем, что такое пагинация, как мы на самом деле ее используем? И почему она необходима?
🔍 Типы пагинации
Существует две широко используемые стратегии пагинации — offset и cursor. Прежде чем углубиться и узнать о них все, давайте посмотрим на некоторые веб-сайты, которые их используют.
Сначала давайте посетим страницу Stargazer на GitHub и заметим, что на вкладке написано 5,000+, а не абсолютное число? Также, вместо стандартных номеров страниц, они используют кнопки Previous (Назад) и Next (Далее).

Теперь переключимся на список продуктов Amazon и заметим точное количество результатов 364 и стандартную пагинацию со всеми номерами страниц, по которым вы можете кликать 1 2 3 … 20.

Совершенно очевидно, что два технологических гиганта не смогли договориться о том, какое решение лучше! Почему? Что ж, нам придется использовать ответ, который ненавидят разработчики: Это зависит от обстоятельств. Давайте рассмотрим оба метода, чтобы понять их преимущества, ограничения и влияние на производительность.
Offset pagination (Offset-пагинация)
Большинство веб-сайтов используют offset-пагинацию из-за ее простоты и того, насколько интуитивно понятна пагинация для пользователей. Для реализации offset-пагинации нам обычно нужны две части информации:
limit- Количество строк для извлечения из базы данныхoffset- Количество строк для пропуска. Offset (смещение) похож на номер страницы, но с небольшой математикой вокруг него(offset = (page-1) * limit)
Чтобы получить первую страницу наших данных, мы устанавливаем limit равным 10 (потому что мы хотим 10 элементов на странице) и offset равным 0 (потому что мы хотим начать отсчет 10 элементов с 0-го элемента). В результате мы получим десять строк.
Чтобы получить вторую страницу, мы сохраняем limit равным 10 (это не меняется, так как мы хотим, чтобы каждая страница содержала 10 строк) и устанавливаем offset равным 10 (возвращаем результаты, начиная с 10-й строки). Мы продолжаем этот подход, позволяя конечному пользователю перелистывать результаты и просматривать весь свой контент.
В мире SQL такой запрос был бы записан как SELECT * FROM posts OFFSET 10 LIMIT 10.
Некоторые веб-сайты, реализующие offset-пагинацию, также показывают номер последней страницы. Как они это делают? Наряду с результатами для каждой страницы они также обычно возвращают атрибут sum, который сообщает вам, сколько всего существует строк. Используя limit, sum и немного математики, вы можете вычислить номер последней страницы, используя lastPage = ceil(sum / limit)
Какой бы удобной ни была эта функция для пользователя, разработчики с трудом масштабируют этот тип пагинации. Глядя на атрибут sum, мы уже видим, что подсчет всех строк в базе данных до точного числа может занять довольно много времени. Кроме того, смещение (offset) в базе данных реализовано таким образом, что оно итерируется по строкам, чтобы знать, сколько их нужно пропустить. Это означает, что чем выше наше смещение, тем дольше будет выполняться наш запрос к базе данных.
Еще одним недостатком offset-пагинации является то, что она НЕ работает хорошо с данными в реальном времени или часто меняющимися данными. Смещение говорит, сколько строк мы хотим пропустить, но НЕ учитывает удаление строк или создание новых строк. Такое смещение может привести к отображению дублирующихся данных или некоторых пропущенных данных.
Cursor pagination (Cursor-пагинация)
Курсоры являются преемниками смещения, так как они решают все проблемы, которые есть у offset-пагинации — производительность, пропущенные данные и дублирование данных, потому что она не полагается на относительный порядок строк, как в случае с offset-пагинацией. Вместо этого она полагается на созданный индекс, управляемый базой данных. Для реализации cursor-пагинации нам понадобится следующая информация:
limit- Как и раньше, количество строк, которые мы хотим показать на одной страницеcursor- ID опорного элемента в списке. Это может бытьпервый элемент, если вы запрашиваетепредыдущую страницу, ипоследний элемент, если запрашиваетеследующую страницу.cursorDirection- Нажал ли пользователь на Next или Previous (после или до)
При запросе первой страницы нам не нужно ничего указывать, только limit 10, сообщая, сколько строк мы хотим получить. В результате мы получаем наши десять строк.
Чтобы получить следующую страницу, мы используем ID последней строки в качестве cursor и устанавливаем cursorDirection на after.
Аналогично, если мы хотим перейти на предыдущую страницу, мы используем ID первой строки в качестве cursor и устанавливаем direction на before.
Для сравнения, в мире SQL мы могли бы написать наш запрос как SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC.
Запросы, использующие cursor вместо offset, более производительны, потому что запрос WHERE помогает пропускать нежелательные строки, в то время как OFFSET должен итерироваться по ним, что приводит к полному сканированию таблицы (full-table scan). Пропуск строк с использованием WHERE может быть еще быстрее, если вы настроите соответствующие индексы для ваших ID. Индекс создается по умолчанию в случае вашего первичного ключа.
Мало того, вам больше не нужно беспокоиться о том, что строки вставляются или удаляются. Если бы вы использовали смещение 10, вы бы ожидали, что перед вашей текущей страницей будет ровно 10 строк. Если это условие не будет выполнено, ваш запрос вернет непоследовательные результаты, что приведет к дублированию данных и даже пропущенным строкам. Это может произойти, если какая-либо из строк перед вашей текущей страницей была удалена или были добавлены новые строки. Cursor-пагинация решает это, используя индекс последней строки, которую вы извлекли, и она знает точно, где начать поиск, когда вы запрашиваете больше.
Не все так радужно. Cursor-пагинация — это действительно сложная проблема, если вам нужно реализовать ее на бэкенде самостоятельно. Для реализации cursor-пагинации вам понадобятся условия WHERE и ORDER BY в вашем запросе. Кроме того, вам также понадобятся условия WHERE для фильтрации по вашим требуемым условиям. Это может стать довольно сложным очень быстро, и вы можете получить огромный вложенный запрос. Кроме того, вам также нужно будет создать индексы для всех столбцов, которые вам нужно запрашивать.
Отлично! Мы избавились от дубликатов и пропущенных данных, переключившись на cursor-пагинацию! Но у нас осталась одна проблема. Поскольку вы НЕ ДОЛЖНЫ раскрывать пользователю инкрементные числовые ID (по соображениям безопасности), теперь вы должны поддерживать хешированную версию каждого ID. Всякий раз, когда вам нужно запросить базу данных, вы преобразуете этот строковый ID в его числовой ID, просматривая таблицу, содержащую эти пары. Что произойдет, если эта строка отсутствует? Что произойдет, если вы нажмете кнопку «Далее», возьмете ID последней строки и запросите следующую страницу, но база данных не сможет найти ID?
Это действительно редкое условие, и оно случается только в том случае, если ID строки, которую вы собираетесь использовать в качестве курсора, только что был удален. Мы можем решить эту проблему, попробовав предыдущие строки или повторно получив данные предыдущих запросов, чтобы обновить последнюю строку новым ID, но все это привносит совершенно новый уровень сложности, и разработчику нужно понимать кучу новых концепций, таких как рекурсия и правильное управление состоянием. К счастью, такие сервисы, как Appwrite, заботятся об этом, поэтому вы можете просто использовать cursor-пагинацию как функцию.
🚀 Пагинация в Appwrite
Appwrite — это backend-as-a-service с открытым исходным кодом, который абстрагирует всю сложность, связанную с созданием современного приложения, предоставляя вам набор REST API для ваших основных потребностей бэкенда. Appwrite обрабатывает аутентификацию и авторизацию пользователей, базы данных, хранение файлов, облачные функции, веб-хуки и многое другое! Если чего-то не хватает, вы можете расширить Appwrite, используя свой любимый язык бэкенда.
База данных Appwrite позволяет хранить любые текстовые данные, которыми необходимо обмениваться между вашими пользователями. База данных Appwrite позволяет создавать несколько коллекций (таблиц) и хранить в них несколько документов (строк). Каждая коллекция имеет настроенные атрибуты (столбцы), чтобы придать вашему набору данных правильную схему. Вы также можете настроить индексы, чтобы сделать ваши поисковые запросы более производительными. При чтении ваших данных вы можете использовать множество мощных запросов, фильтровать их, сортировать их, ограничивать количество результатов и разбивать их на страницы. И все это доступно из коробки!
Что делает базу данных Appwrite еще лучше, так это поддержка пагинации в Appwrite, поскольку мы поддерживаем как offset, так и cursor-пагинацию! Давайте представим, что у нас есть коллекция с ID articles, мы можем получать документы из этой коллекции с помощью offset или cursor-пагинации:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
Сначала мы импортируем библиотеку Appwrite SDK и настраиваем экземпляр, подключенный к определенному экземпляру Appwrite и определенному проекту. Затем мы перечисляем 10 документов, используя offset-пагинацию, при этом имея фильтр для отображения только опубликованных. Сразу после этого мы пишем точно такой же запрос списка документов, но на этот раз используя cursor вместо offset-пагинации.
📊 Бенчмарки (Benchmarks)
Мы довольно часто использовали слово производительность в этой статье, не приводя никаких реальных цифр, так что давайте создадим бенчмарк вместе! Мы будем использовать Appwrite в качестве нашего бэкенд-сервера, потому что он поддерживает offset и cursor-пагинацию, и Node.JS для написания скриптов бенчмарка. В конце концов, Javascript довольно прост для понимания.
Вы можете найти полный исходный код в виде репозитория GitHub.
Сначала мы настраиваем Appwrite, регистрируем пользователя, создаем проект и создаем коллекцию с именем posts с разрешением уровня коллекции и разрешением на чтение, установленным на role:all. Чтобы узнать больше об этом процессе, посетите документацию Appwrite. Теперь у нас должен быть готов к использованию Appwrite.
Мы пока не можем провести бенчмарк, потому что наша база данных пуста! Давайте заполним нашу таблицу некоторыми данными. Мы используем следующий скрипт для загрузки данных в нашу базу данных MariadDB и подготовки к бенчмарку.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
Мы использовали два слоя циклов for для увеличения скорости скрипта. Первый цикл for создает выполнения запросов, которые нужно ожидать, а второй цикл создает длинный запрос, содержащий несколько запросов на вставку. В идеале мы хотели бы все в одном запросе, но это невозможно из-за конфигурации MySQL, поэтому мы разделили его на 100 запросов.
У нас есть 1 миллион документов, вставленных менее чем за минуту, и мы готовы начать наши бенчмарки. Мы будем использовать библиотеку нагрузочного тестирования k6 для этой демонстрации.
Давайте сначала протестируем хорошо известную и широко используемую offset-пагинацию. Во время каждого сценария тестирования мы пытаемся получить страницу с 10 документами из разных частей нашего набора данных. Мы начнем со смещения 0 и дойдем до смещения 900k с шагом 100k. Бенчмарк написан таким образом, что он делает только один запрос за раз, чтобы быть максимально точным. Мы также запустим один и тот же бенчмарк десять раз и измерим среднее время отклика, чтобы обеспечить статистическую значимость. Мы будем использовать HTTP-клиент k6 для выполнения запросов к REST API Appwrite.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
Для запуска бенчмарка с различными конфигурациями смещения и сохранения вывода в CSV-файлы я создал простой bash-скрипт. Этот скрипт выполняет k6 десять раз, каждый раз с разной конфигурацией смещения. Вывод будет предоставлен в виде вывода консоли.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
В течение минуты все бенчмарки завершились и предоставили мне среднее время отклика для каждой конфигурации смещения. Результаты были ожидаемыми, но совсем не удовлетворительными.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
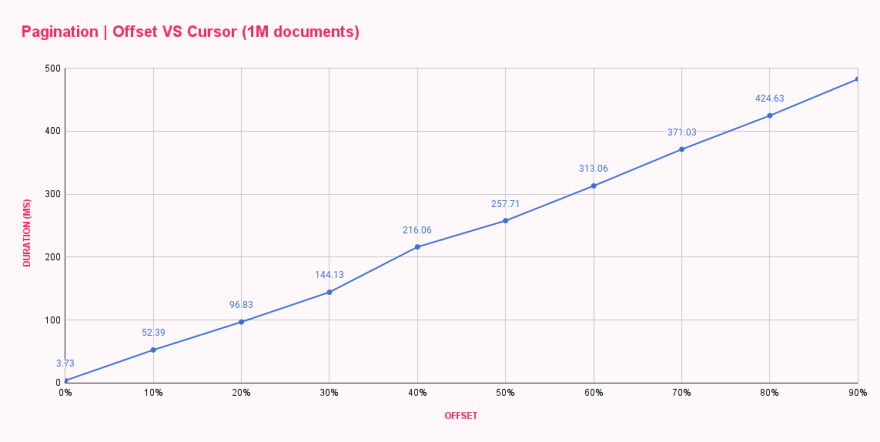
Как мы видим, offset 0 был довольно быстрым, отвечая менее чем за 4ms. Наш первый скачок был к offset 100k, и изменение было радикальным, увеличив время отклика до 52ms. С каждым увеличением смещения продолжительность росла, что привело к почти 500ms для получения десяти документов после смещения 900k документов. Это безумие!
Теперь давайте обновим наш скрипт для использования cursor-пагинации. Мы обновим наш скрипт для использования курсора вместо смещения и обновим наш bash-скрипт для предоставления курсора (ID документа) вместо номера смещения.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
После запуска скрипта мы уже могли сказать, что производительность выросла, так как были заметные различия во времени отклика. Мы поместили результаты в таблицу, чтобы сравнить эти два метода пагинации бок о бок.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
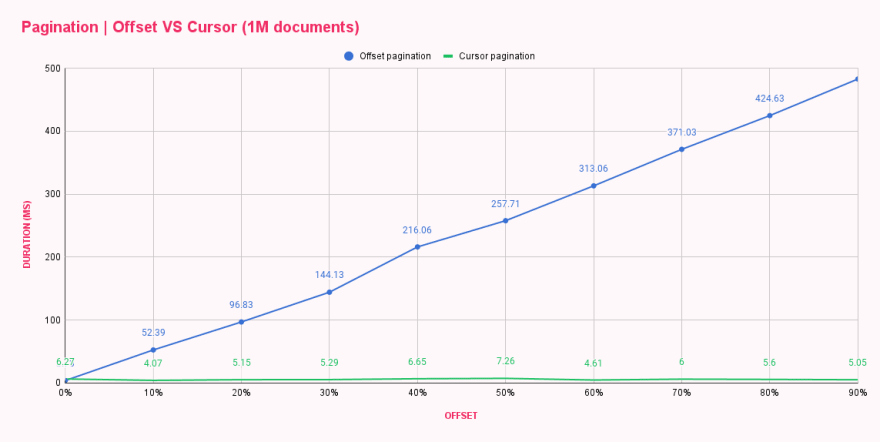
Вау! Cursor-пагинация — это круто! График показывает, что cursor-пагинация НЕ ЗАБОТИТСЯ о размере смещения, и каждый запрос так же эффективен, как первый или последний. Вы можете себе представить, какой ущерб может быть нанесен многократной загрузкой последней страницы огромного списка? 😬
Если вам интересно запустить тесты на своей собственной машине, вы можете найти полный исходный код как репозиторий GitHub. Репозиторий включает README.md, объясняющий весь процесс установки и запуска скриптов.
👨🎓 Резюме
Offset-пагинация предлагает хорошо известный метод пагинации, где вы можете видеть номера страниц и кликать по ним. Этот интуитивно понятный метод имеет кучу недостатков, таких как ужасная производительность при высоком смещении и возможность дублирования данных и пропущенных данных.
Cursor-пагинация решает все эти проблемы и предлагает надежную систему пагинации, которая работает быстро и может обрабатывать данные в реальном времени (часто меняющиеся). Недостатком cursor-пагинации является ОТСУТСТВИЕ номеров страниц, сложность ее реализации и новый набор проблем, которые нужно преодолеть, например, отсутствующие ID курсоров.
Теперь вернемся к нашему первоначальному вопросу: почему GitHub использует cursor-пагинацию, а Amazon решила использовать offset-пагинацию? Производительность не всегда является ключом… Опыт пользователя намного ценнее, чем количество серверов, за которые должна платить ваша компания.
Я считаю, что Amazon решила использовать смещение, потому что это улучшает UX, но это тема для другого исследования. Мы уже можем заметить, что если мы зайдем на amazon.com и поищем ручку, он скажет, что есть ровно 10 000 результатов, но вы можете посетить только первые семь страниц (350 результатов).
Во-первых, результатов гораздо больше, чем просто 10 тысяч, но Amazon ограничивает это. Во-вторых, вы все равно можете посетить первые семь страниц. Если вы попытаетесь посетить страницу 8, она покажет ошибку 404. Как мы видим, Amazon знает о производительности offset-пагинации, но все же решила оставить ее, потому что их пользовательская база предпочитает видеть номера страниц. Им пришлось включить некоторые ограничения, но кто вообще ходит на 100-ю страницу результатов поиска? 🤷
Знаете, что лучше, чем читать о пагинации? Попробовать ее! Я призываю вас попробовать оба метода, потому что лучше всего получить личный опыт. Настройка Appwrite занимает менее нескольких минут, и вы можете начать играть с обоими методами пагинации. Если у вас есть какие-либо вопросы, вы также можете связаться с нами на нашем сервере Discord.