
Photo by Tobias Fischer on Unsplash
👋 Introdução
O Banco de Dados é um dos pilares de toda aplicação. É onde você armazena tudo o que seu aplicativo precisa lembrar, computar mais tarde ou exibir para outros usuários online. Tudo é diversão e jogos até que o banco de dados cresce e seu aplicativo começa a travar porque você estava tentando buscar e renderizar 1.000 postagens de uma vez. Bem, você é um engenheiro inteligente, certo? Você rapidamente corrige isso com um botão “Mostrar mais”. Algumas semanas depois, você se depara com um novo erro de Timeout! Você vai para o Stack Overflow, mas rapidamente percebe que Ctrl e V pararam de funcionar devido ao uso excessivo 🤦 Sem mais opções à sua disposição, você realmente começa a depurar e percebe que o banco de dados retorna mais de 50.000 postagens toda vez que um usuário abre seu aplicativo! O que fazemos agora?

Para evitar esses cenários horríveis, devemos estar cientes dos riscos desde o início, porque um desenvolvedor bem preparado nunca terá que arriscar. Este artigo irá prepará-lo para combater problemas de desempenho relacionados ao banco de dados usando offset e cursor pagination.
“Uma onça de prevenção vale uma libra de cura.” - Benjamin Franklin
📚 O que é paginação?
Paginação é uma estratégia empregada ao consultar qualquer conjunto de dados que contenha mais do que apenas algumas centenas de registros. Graças à paginação, podemos dividir nosso grande conjunto de dados em pedaços (ou páginas) que podemos buscar e exibir gradualmente para o usuário, reduzindo assim a carga no banco de dados. A paginação também resolve muitos problemas de desempenho tanto no lado do cliente quanto no servidor! Sem paginação, você teria que carregar todo o histórico de bate-papo apenas para ler a última mensagem enviada a você.
Hoje em dia, a paginação quase se tornou uma necessidade, já que é muito provável que todas as aplicações lidem com grandes quantidades de dados. Esses dados podem ser qualquer coisa, desde conteúdo gerado pelo usuário, conteúdo adicionado por administradores ou editores, ou auditorias e logs gerados automaticamente. Assim que sua lista crescer para mais de alguns milhares de itens, seu banco de dados levará muito tempo para resolver cada solicitação e a velocidade e acessibilidade do seu front-end serão afetadas. Quanto aos seus usuários, a experiência deles será algo assim.

Agora que sabemos o que é paginação, como realmente a usamos? E por que ela é necessária?
🔍 Tipos de paginação
Existem duas estratégias de paginação amplamente utilizadas - offset e cursor. Antes de nos aprofundarmos e aprendermos tudo sobre elas, vamos ver alguns sites que as utilizam.
Primeiro, vamos visitar a página Stargazer do GitHub e notar como a guia diz 5,000+ e não um número absoluto? Além disso, em vez de números de página padrão, eles usam botões Previous (Anterior) e Next (Próximo).

Agora, vamos mudar para a lista de produtos da Amazon e notar a quantidade exata de resultados 364, e a paginação padrão com todos os números de páginas em que você pode clicar 1 2 3 … 20.

É muito claro que dois gigantes da tecnologia não conseguiram concordar sobre qual solução é melhor! Por quê? Bem, teremos que usar uma resposta que os desenvolvedores odeiam: Depende. Vamos explorar ambos os métodos para entender suas vantagens, limitações e implicações de desempenho.
Offset pagination (Paginação Offset)
A maioria dos sites usa paginação offset devido à sua simplicidade e ao quão intuitiva a paginação é para os usuários. Para implementar a paginação offset, geralmente precisamos de duas informações:
limit- Número de linhas para buscar do banco de dadosoffset- Número de linhas para pular. Offset é como um número de página, mas com um pouco de matemática em torno dele(offset = (page-1) * limit)
Para obter a primeira página de nossos dados, definimos o limit para 10 (porque queremos 10 itens na página) e o offset para 0 (porque queremos começar a contar 10 itens a partir do item 0). Como resultado, obteremos dez linhas.
Para obter a segunda página, mantemos o limit em 10 (isso não muda, pois queremos que cada página contenha 10 linhas) e definimos o offset para 10 (retorna resultados da 10ª linha em diante). Continuamos com essa abordagem, permitindo assim que o usuário final pagine pelos resultados e veja todo o seu conteúdo.
No mundo SQL, tal consulta seria escrita como SELECT * FROM posts OFFSET 10 LIMIT 10.
Alguns sites que implementam paginação offset também mostram o número da página da última página. Como eles fazem isso? Junto com os resultados para cada página, eles também tendem a retornar um atributo sum que informa quantas linhas existem no total. Usando limit, sum e um pouco de matemática, você pode calcular o número da última página usando lastPage = ceil(sum / limit)
Por mais conveniente que esse recurso seja para o usuário, os desenvolvedores lutam para escalar esse tipo de paginação. Olhando para o atributo sum, já podemos ver que pode levar bastante tempo para contar todas as linhas em um banco de dados para o número exato. Além disso, o offset no banco de dados é implementado de tal forma que ele itera pelas linhas para saber quantas devem ser puladas. Isso significa que quanto maior o nosso offset, mais tempo nossa consulta ao banco de dados levará.
Outra desvantagem da paginação offset é que ela NÃO funciona bem com dados em tempo real ou dados que mudam frequentemente. O offset diz quantas linhas queremos pular, mas NÃO leva em conta a exclusão de linhas ou a criação de novas linhas. Tal offset pode resultar na exibição de dados duplicados ou em alguns dados ausentes.
Cursor pagination (Paginação Cursor)
Cursores são sucessores do offset, pois resolvem todos os problemas que a paginação offset tem - desempenho, dados ausentes e duplicação de dados, pois não depende da ordem relativa das linhas como no caso da paginação offset. Em vez disso, depende de um índice criado e gerenciado pelo banco de dados. Para implementar a paginação cursor, precisaremos das seguintes informações:
limit- O mesmo de antes, quantidade de linhas que queremos mostrar em uma única páginacursor- ID de um elemento de referência na lista. Pode ser oprimeiro itemse você estiver consultando apágina anteriore oúltimo itemse estiver consultando apróxima página.cursorDirection- Se o usuário clicou em Next ou Previous (depois ou antes)
Ao solicitar a primeira página, não precisamos fornecer nada, apenas limit 10, dizendo quantas linhas queremos obter. Como resultado, obtemos nossas dez linhas.
Para obter a próxima página, usamos o ID da última linha como o cursor e definimos cursorDirection para after.
Da mesma forma, se quisermos ir para a página anterior, usamos o ID da primeira linha como cursor e definimos direction para before.
Para comparar, no mundo SQL, poderíamos escrever nossa consulta como SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC.
Consultas que usam um cursor em vez de offset têm melhor desempenho porque a consulta WHERE ajuda a pular linhas indesejadas, enquanto OFFSET precisa iterar sobre elas, resultando em uma verificação completa da tabela (full-table scan). Pular linhas usando WHERE pode ser ainda mais rápido se você configurar índices adequados em seus IDs. O índice é criado por padrão no caso de sua chave primária.
Não só isso, você não precisa mais se preocupar com linhas sendo inseridas ou excluídas. Se você estivesse usando um deslocamento de 10, esperaria que exatamente 10 linhas estivessem presentes antes de sua página atual. Se essa condição não for atendida, sua consulta retornará resultados inconsistentes, levando à duplicação de dados e até mesmo a linhas ausentes. Isso pode acontecer se qualquer uma das linhas à frente de sua página atual foi excluída ou novas linhas adicionadas. A paginação cursor resolve isso usando o índice da última linha que você buscou e sabe exatamente onde começar a procurar, quando você solicita mais.
Nem tudo são flores. Paginação cursor é um problema realmente complexo se você precisar implementá-lo no backend por conta própria. Para implementar a paginação cursor, você precisará de cláusulas WHERE e ORDER BY em sua consulta. Além disso, você também precisará de cláusulas WHERE para filtrar por suas condições necessárias. Isso pode se tornar bastante complexo muito rapidamente e você pode acabar com uma enorme consulta aninhada. Além disso, você também precisará criar índices para todas as colunas que precisa consultar.
Ótimo! Nos livramos de duplicatas e dados ausentes mudando para a paginação cursor! Mas ainda temos um problema restante. Como você NÃO DEVE expor IDs numéricos incrementais ao usuário (por motivos de segurança), agora você deve manter uma versão hash de cada ID. Sempre que precisar consultar um banco de dados, você converte esse ID de string em seu ID numérico observando uma tabela que contém esses pares. E se esta linha estiver faltando? E se você clicar no botão Next, pegar o ID da última linha e solicitar a próxima página, mas o banco de dados não conseguir encontrar o ID?
Esta é uma condição muito rara e só acontece se o ID da linha que você está prestes a usar como cursor tiver acabado de ser excluído. Podemos resolver esse problema tentando linhas anteriores ou buscando novamente os dados das solicitações anteriores para atualizar a última linha com um novo ID, mas tudo isso traz um nível totalmente novo de complexidade, e o desenvolvedor precisa entender um monte de novos conceitos, como recursão e gerenciamento de estado adequado. Felizmente, serviços como Appwrite cuidam disso, então você pode simplesmente usar a paginação cursor como um recurso.
🚀 Paginação no Appwrite
Appwrite é um backend-as-a-service de código aberto que abstrai toda a complexidade envolvida na construção de um aplicativo moderno, fornecendo a você um conjunto de APIs REST para suas principais necessidades de backend. O Appwrite lida com autenticação e autorização de usuários, bancos de dados, armazenamento de arquivos, funções de nuvem, webhooks e muito mais! Se faltar alguma coisa, você pode estender o Appwrite usando sua linguagem de backend favorita.
O Appwrite Database permite armazenar quaisquer dados baseados em texto que precisem ser compartilhados entre seus usuários. O banco de dados do Appwrite permite criar várias coleções (tabelas) e armazenar vários documentos (linhas) nele. Cada coleção tem atributos (colunas) configurados para dar ao seu conjunto de dados um esquema adequado. Você também pode configurar índices para tornar suas consultas de pesquisa mais performáticas. Ao ler seus dados, você pode usar uma série de consultas poderosas, filtrá-las, classificá-las, limitar o número de resultados e paginar sobre elas. E tudo isso vem pronto para uso!
O que torna o Appwrite Database ainda melhor é o suporte de paginação do Appwrite, pois suportamos paginação offset e cursor! Vamos imaginar que temos uma coleção com ID articles, podemos obter documentos desta coleção com paginação offset ou cursor:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
Primeiro, importamos a biblioteca Appwrite SDK e configuramos uma instância conectada a uma instância específica do Appwrite e a um projeto específico. Em seguida, listamos 10 documentos usando paginação offset enquanto temos um filtro para mostrar apenas aqueles que são publicados. Logo depois, escrevemos exatamente a mesma consulta de lista de documentos, mas desta vez usando paginação cursor em vez de offset.
📊 Benchmarks
Usamos a palavra desempenho com bastante frequência neste artigo sem fornecer números reais, então vamos criar um benchmark juntos! Usaremos o Appwrite como nosso servidor backend porque ele suporta paginação offset e cursor e Node.JS para escrever os scripts de benchmark. Afinal, Javascript é muito fácil de seguir.
Você pode encontrar o código-fonte completo como repositório GitHub.
Primeiro, configuramos o Appwrite, registramos um usuário, criamos um projeto e criamos uma coleção chamada posts com permissão de nível de coleção e permissão de leitura definida como role:all. Para saber mais sobre esse processo, visite a documentação do Appwrite. Agora devemos ter o Appwrite pronto para ser utilizado.
Ainda não podemos fazer o benchmark, porque nosso banco de dados está vazio! Vamos preencher nossa tabela com alguns dados. Usamos o seguinte script para carregar dados em nosso banco de dados MariadDB e nos preparar para o benchmark.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
Usamos duas camadas de loops for para aumentar a velocidade do script. O primeiro loop for cria execuções de consulta que precisam ser aguardadas, e o segundo loop cria uma consulta longa contendo várias solicitações de inserção. Idealmente, gostaríamos de tudo em uma única solicitação, mas isso é impossível devido à configuração do MySQL, então dividimos em 100 solicitações.
Temos 1 milhão de documentos inseridos em menos de um minuto e estamos prontos para iniciar nossos benchmarks. Usaremos a biblioteca de teste de carga k6 para esta demonstração.
Vamos fazer um benchmark da paginação offset bem conhecida e amplamente utilizada primeiro. Durante cada cenário de teste, tentamos buscar uma página com 10 documentos, de diferentes partes do nosso conjunto de dados. Começaremos com o deslocamento 0 e iremos até o deslocamento de 900k em incrementos de 100k. O benchmark é escrito de forma que faça apenas uma solicitação de cada vez para mantê-lo o mais preciso possível. Também executaremos o mesmo benchmark dez vezes e mediremos os tempos médios de resposta para garantir significância estatística. Usaremos o cliente HTTP k6 para fazer solicitações à API REST do Appwrite.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
Para executar o benchmark com diferentes configurações de deslocamento e armazenar a saída em arquivos CSV, criei um script bash simples. Este script executa k6 dez vezes, com uma configuração de deslocamento diferente a cada vez. A saída será fornecida como saída do console.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
Em um minuto, todos os benchmarks terminaram e me forneceram o tempo médio de resposta para cada configuração de deslocamento. Os resultados foram os esperados, mas nada satisfatórios.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
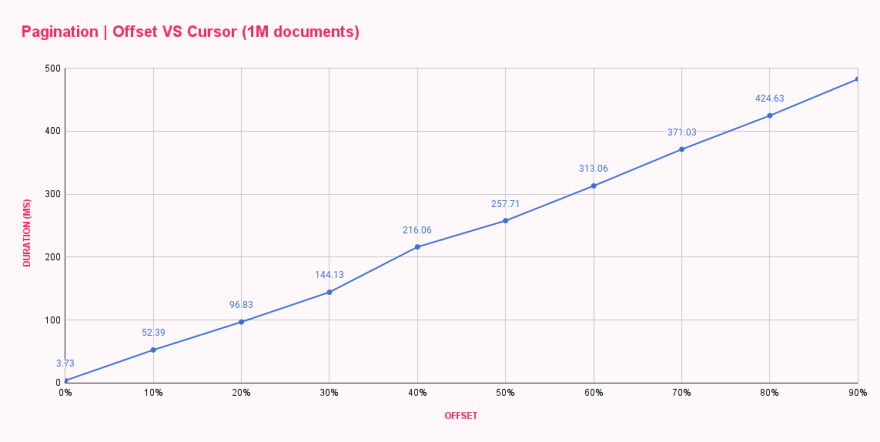
Como podemos ver, o offset 0 foi muito rápido, respondendo em menos de 4ms. Nosso primeiro salto foi para o offset 100k, e a mudança foi drástica, aumentando os tempos de resposta para 52ms. A cada aumento no deslocamento, a duração aumentava, resultando em quase 500ms para obter dez documentos após o deslocamento de 900k documentos. Isso é loucura!
Agora vamos atualizar nosso script para usar paginação cursor. Atualizaremos nosso script para usar cursor em vez de offset e atualizaremos nosso script bash para fornecer cursor (ID do documento) em vez do número de deslocamento.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
Depois de executar o script, já podíamos dizer que houve um aumento de desempenho, pois houve diferenças notáveis nos tempos de resposta. Colocamos os resultados em uma tabela para comparar esses dois métodos de paginação lado a lado.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
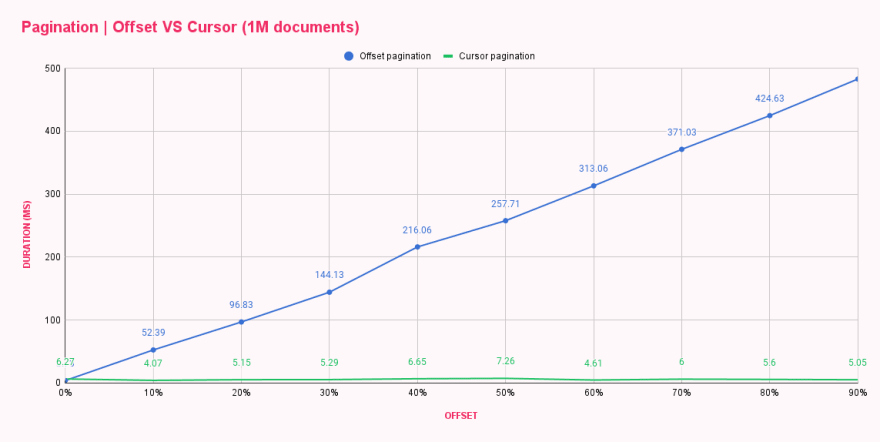
Uau! Paginação cursor é legal! O gráfico mostra que a paginação cursor NÃO SE IMPORTA com o tamanho do deslocamento, e cada consulta é tão eficiente quanto a primeira ou a última. Você consegue imaginar o quanto de dano pode ser feito carregando repetidamente a última página de uma lista enorme? 😬
Se você estiver interessado em executar testes em sua própria máquina, poderá encontrar o código-fonte completo como repositório GitHub. O repositório inclui um README.md explicando todo o processo de instalação e execução de scripts.
👨🎓 Resumo
Paginação offset oferece um método de paginação bem conhecido, onde você pode ver os números das páginas e clicar neles. Esse método intuitivo vem com várias desvantagens, como desempenho terrível com deslocamentos altos e a possibilidade de duplicação de dados e dados ausentes.
Paginação cursor resolve todos esses problemas e traz um sistema de paginação confiável, rápido e capaz de lidar com dados em tempo real (que mudam frequentemente). A desvantagem da paginação cursor é NÃO EXIBIR números de página, sua complexidade de implementação e um novo conjunto de desafios a serem superados, como a falta de ID de cursor.
Agora, voltando à nossa pergunta original, por que o GitHub usa paginação cursor, mas a Amazon decidiu usar paginação offset? O desempenho nem sempre é a chave… A experiência do usuário é muito mais valiosa do que a quantidade de servidores que sua empresa precisa pagar.
Acredito que a Amazon decidiu usar offset porque melhora a UX, mas esse é um tópico para outra pesquisa. Já podemos notar que se visitarmos amazon.com e procurarmos uma caneta, diz que existem exatamente 10 000 resultados, mas você só pode visitar as primeiras sete páginas (350 resultados).
Primeiro, há muito mais do que apenas 10 mil resultados, mas a Amazon limita isso. Em segundo lugar, você pode visitar as primeiras sete páginas de qualquer maneira. Se você tentar visitar a página 8, ela mostrará um erro 404. Como podemos ver, a Amazon está ciente do desempenho da paginação offset, mas ainda decidiu mantê-la porque sua base de usuários prefere ver números de página. Eles tiveram que incluir alguns limites, mas quem vai para a página 100 dos resultados da pesquisa de qualquer maneira? 🤷
Você sabe o que é melhor do que ler sobre paginação? Experimentá-la! Encorajo você a experimentar os dois métodos porque é melhor ter experiência em primeira mão. A configuração do Appwrite leva menos de alguns minutos e você pode começar a brincar com os dois métodos de paginação. Se você tiver alguma dúvida, também pode entrar em contato conosco em nosso servidor Discord.