
Photo by Tobias Fischer on Unsplash
👋 들어가며
데이터베이스는 모든 애플리케이션의 초석 중 하나입니다. 앱이 기억하고, 나중에 계산하고, 온라인의 다른 사용자에게 표시하는 데 필요한 모든 것을 저장하는 곳입니다. 데이터베이스가 커지고 한 번에 1,000개의 게시물을 가져와 렌더링하려고 하여 애플리케이션이 느려지기 시작할 때까지는 모든 것이 재미있습니다. 당신은 똑똑한 엔지니어죠? 당신은 “더 보기” 버튼으로 빠르게 문제를 해결합니다. 몇 주 후, 새로운 시간 초과(Timeout) 오류가 발생합니다! Stack Overflow로 향하지만 과도한 사용으로 인해 Ctrl과 V가 작동을 멈췄다는 것을 금방 깨닫습니다 🤦 더 이상 선택지가 없어 실제로 디버깅을 시작하고 데이터베이스가 사용자가 앱을 열 때마다 50,000개 이상의 게시물을 반환한다는 것을 깨닫습니다! 이제 어떻게 해야 할까요?

이러한 끔찍한 시나리오를 방지하기 위해 우리는 처음부터 위험을 인식해야 합니다. 잘 준비된 개발자는 위험을 감수할 필요가 없기 때문입니다. 이 글은 offset(오프셋) 및 cursor pagination(커서 페이지네이션)을 사용하여 데이터베이스 관련 성능 문제에 대처할 수 있도록 준비시켜 줄 것입니다.
“예방이 치료보다 낫다.” - 벤자민 프랭클린
📚 페이지네이션이란 무엇인가요?
페이지네이션은 수백 개의 레코드 이상을 보유한 데이터 세트를 쿼리할 때 사용되는 전략입니다. 페이지네이션 덕분에 우리는 대규모 데이터 세트를 점차적으로 가져와 사용자에게 표시할 수 있는 청크(또는 페이지)로 나눌 수 있어 데이터베이스의 부하를 줄일 수 있습니다. 페이지네이션은 클라이언트와 서버 측 모두에서 많은 성능 문제를 해결합니다! 페이지네이션이 없다면 당신에게 전송된 최신 메시지를 읽기 위해 전체 채팅 기록을 로드해야 할 것입니다.
요즘에는 모든 애플리케이션이 많은 양의 데이터를 다룰 가능성이 높기 때문에 페이지네이션은 거의 필수 요소가 되었습니다. 이 데이터는 사용자 생성 콘텐츠, 관리자나 편집자가 추가한 콘텐츠, 또는 자동으로 생성된 감사 로그 등 무엇이든 될 수 있습니다. 목록이 몇 천 개 이상의 항목으로 늘어나자마자 데이터베이스는 각 요청을 해결하는 데 너무 오래 걸리고 프론트엔드의 속도와 접근성이 저하됩니다. 사용자의 경우 그들의 경험은 다음과 같을 것입니다.

이제 페이지네이션이 무엇인지 알았으니 실제로 어떻게 사용할까요? 그리고 왜 필요할까요?
🔍 페이지네이션의 종류
널리 사용되는 두 가지 페이지네이션 전략인 offset과 cursor가 있습니다. 깊이 파고들어 모든 것을 배우기 전에 이를 사용하는 몇 가지 웹사이트를 살펴보겠습니다.
먼저 GitHub의 Stargazer 페이지를 방문하여 탭에 절대 숫자 대신 5,000+라고 표시되는 것을 주목하세요. 또한 표준 페이지 번호 대신 Previous(이전) 및 Next(다음) 버튼을 사용합니다.

이제 Amazon의 제품 목록으로 전환하여 정확한 결과 수 364개와 1 2 3 … 20을 클릭할 수 있는 모든 페이지 번호가 있는 표준 페이지네이션에 주목하세요.

두 거대 기술 기업이 어떤 솔루션이 더 나은지에 대해 동의할 수 없었다는 것은 분명합니다! 왜 그럴까요? 글쎄요, 개발자들이 싫어하는 대답인 “상황에 따라 다릅니다"를 사용해야 합니다. 두 가지 방법을 모두 살펴보고 장점, 한계 및 성능에 미치는 영향을 이해해 봅시다.
Offset pagination (오프셋 페이지네이션)
대부분의 웹사이트는 단순성과 사용자에게 페이지네이션이 얼마나 직관적인지 때문에 오프셋 페이지네이션을 사용합니다. 오프셋 페이지네이션을 구현하려면 일반적으로 두 가지 정보가 필요합니다.
limit- 데이터베이스에서 가져올 행 수offset- 건너뛸 행 수. 오프셋은 페이지 번호와 같지만 약간의 수학적 계산이 필요합니다(offset = (page-1) * limit)
데이터의 첫 페이지를 가져오려면 limit를 10으로 설정(페이지에 10개의 항목을 원하기 때문)하고 offset을 0으로 설정(0번째 항목부터 10개 항목을 카운트하기 시작하기 때문)합니다. 결과적으로 10개의 행을 얻게 됩니다.
두 번째 페이지를 가져오려면 limit를 10으로 유지(모든 페이지에 10개 행을 원하므로 변경되지 않음)하고 offset을 10으로 설정(10번째 행 이후부터 결과 반환)합니다. 이 접근 방식을 계속하여 최종 사용자가 결과를 페이지별로 넘겨보고 모든 콘텐츠를 볼 수 있도록 합니다.
SQL 세계에서 이러한 쿼리는 SELECT * FROM posts OFFSET 10 LIMIT 10으로 작성됩니다.
오프셋 페이지네이션을 구현하는 일부 웹사이트는 마지막 페이지 번호도 표시합니다. 어떻게 할까요? 각 페이지의 결과와 함께 총 몇 개의 행이 있는지 알려주는 sum 속성도 반환하는 경향이 있습니다. limit, sum 및 약간의 수학을 사용하여 lastPage = ceil(sum / limit)를 사용하여 마지막 페이지 번호를 계산할 수 있습니다.
이 기능은 사용자에게 편리하지만 개발자는 이러한 유형의 페이지네이션을 확장하는 데 어려움을 겪습니다. sum 속성을 보면 데이터베이스의 모든 행을 정확한 숫자로 계산하는 데 꽤 오랜 시간이 걸릴 수 있음을 이미 알 수 있습니다. 게다가 데이터베이스의 오프셋은 얼마나 많은 행을 건너뛰어야 하는지 알기 위해 행을 루프하는 방식으로 구현됩니다. 즉, 오프셋이 높을수록 데이터베이스 쿼리가 더 오래 걸립니다.
오프셋 페이지네이션의 또 다른 단점은 실시간 데이터나 자주 변경되는 데이터와 호환되지 않는다는 것입니다. 오프셋은 건너뛰고 싶은 행의 수를 알려주지만 행 삭제 또는 새로운 행 생성을 고려하지 않습니다. 이러한 오프셋은 중복 데이터를 표시하거나 일부 데이터 누락을 초래할 수 있습니다.
Cursor pagination (커서 페이지네이션)
커서는 오프셋의 후속 제품으로, 오프셋 페이지네이션의 모든 문제인 성능, 데이터 누락 및 데이터 중복을 해결합니다. 이는 오프셋 페이지네이션의 경우처럼 행의 상대적 순서에 의존하지 않기 때문입니다. 대신 데이터베이스에서 생성하고 관리하는 인덱스에 의존합니다. 커서 페이지네이션을 구현하려면 다음 정보가 필요합니다.
limit- 이전과 동일하게 한 페이지에 표시하고 싶은 행 수cursor- 목록에 있는 참조 요소의 ID.이전 페이지를 쿼리하는 경우첫 번째 항목이 될 수 있고다음 페이지를 쿼리하는 경우마지막 항목이 될 수 있습니다.cursorDirection- 사용자가 **Next 또는 Previous(이후 또는 이전)**를 클릭했는지 여부
첫 번째 페이지를 요청할 때 아무것도 제공할 필요가 없으며, 가져오고 싶은 행 수를 나타내는 limit 10만 있으면 됩니다. 결과적으로 10개의 행을 얻습니다.
다음 페이지를 가져오려면 마지막 행의 ID를 cursor로 사용하고 cursorDirection을 after로 설정합니다.
마찬가지로 이전 페이지로 가고 싶다면 첫 번째 행의 ID를 cursor로 사용하고 direction을 before로 설정합니다.
비교하자면 SQL 세계에서는 쿼리를 SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC로 작성할 수 있습니다.
offset 대신 cursor를 사용하는 쿼리는 WHERE 쿼리가 원하지 않는 행을 건너뛰는 데 도움이 되기 때문에 성능이 더 뛰어나지만 OFFSET은 이를 반복해야 하므로 전체 테이블 스캔이 발생합니다. ID에 적절한 인덱스를 설정하면 WHERE를 사용하여 행을 건너뛰는 것이 훨씬 더 빨라질 수 있습니다. 기본 키의 경우 인덱스가 기본적으로 생성됩니다.
뿐만 아니라 행이 삽입되거나 삭제되는 것에 대해 더 이상 걱정할 필요가 없습니다. 오프셋 10을 사용하고 있다면 현재 페이지 앞에 정확히 10개의 행이 있을 것으로 예상합니다. 이 조건이 충족되지 않으면 쿼리가 일관성 없는 결과를 반환하여 데이터 중복 및 심지어 행 누락으로 이어질 수 있습니다. 이는 현재 페이지 앞의 행 중 하나라도 삭제되거나 새 행이 추가되면 발생할 수 있습니다. 커서 페이지네이션은 가져온 마지막 행의 인덱스를 사용하여 이 문제를 해결하며 더 요청할 때 어디서부터 찾아야 할지 정확히 알고 있습니다.
모든 것이 좋기만 한 것은 아닙니다. 커서 페이지네이션은 백엔드에서 직접 구현해야 하는 경우 정말 복잡한 문제입니다. 커서 페이지네이션을 구현하려면 쿼리에 WHERE 및 ORDER BY 절이 필요합니다. 또한 필요한 조건으로 필터링하기 위한 WHERE 절도 필요합니다. 이것은 매우 빠르게 복잡해질 수 있으며 거대한 중첩 쿼리로 끝날 수 있습니다. 그 외에도 쿼리해야 하는 모든 열에 대한 인덱스를 생성해야 합니다.
좋습니다! 커서 페이지네이션으로 전환하여 중복과 누락된 데이터를 제거했습니다! 하지만 아직 한 가지 문제가 남았습니다. 절대로 사용자에게 증가하는 숫자 ID를 노출해서는 안 되므로(보안상의 이유로), 이제 각 ID의 해시된 버전을 유지해야 합니다. 데이터베이스를 쿼리해야 할 때마다 이 쌍을 보유한 테이블을 보고 이 문자열 ID를 숫자 ID로 변환합니다. 이 행이 누락되면 어떻게 될까요? Next 버튼을 클릭하고 마지막 행의 ID를 가져와 다음 페이지를 요청했지만 데이터베이스에서 해당 ID를 찾을 수 없다면 어떻게 될까요?
이것은 정말 드문 조건이며 커서로 사용하려는 행의 ID가 방금 삭제된 경우에만 발생합니다. 이 문제는 이전 행을 시도하거나 이전 요청의 데이터를 다시 가져와 새 ID로 마지막 행을 업데이트함으로써 해결할 수 있지만, 이 모든 것은 완전히 새로운 수준의 복잡성을 가져오며 개발자는 재귀 및 적절한 상태 관리와 같은 많은 새로운 개념을 이해해야 합니다. 다행히 Appwrite와 같은 서비스가 이를 처리하므로 커서 페이지네이션을 기능으로 간단히 사용할 수 있습니다.
🚀 Appwrite에서의 페이지네이션
Appwrite는 핵심 백엔드 요구 사항에 대한 REST API 세트를 제공하여 최신 애플리케이션 구축과 관련된 모든 복잡성을 추상화하는 오픈 소스 Backend-as-a-Service입니다. Appwrite는 사용자 인증 및 승인, 데이터베이스, 파일 저장소, 클라우드 기능, 웹훅 등을 처리합니다! 누락된 것이 있으면 좋아하는 백엔드 언어를 사용하여 Appwrite를 확장할 수 있습니다.
Appwrite Database를 사용하면 사용자 간에 공유해야 하는 텍스트 기반 데이터를 저장할 수 있습니다. Appwrite의 데이터베이스를 사용하면 여러 컬렉션(테이블)을 만들고 그 안에 여러 문서(행)를 저장할 수 있습니다. 각 컬렉션에는 데이터 세트에 적절한 스키마를 제공하도록 구성된 속성(열)이 있습니다. 검색 쿼리의 성능을 높이기 위해 인덱스를 구성할 수도 있습니다. 데이터를 읽을 때 강력한 쿼리를 사용하고, 필터링하고, 정렬하고, 결과 수를 제한하고, 페이지를 나눌 수 있습니다. 그리고 이 모든 것이 즉시 사용 가능합니다!
Appwrite Database를 더욱 훌륭하게 만드는 것은 오프셋 페이지네이션과 커서 페이지네이션을 모두 지원하는 Appwrite의 페이지네이션 지원입니다! ID가 articles인 컬렉션이 있다고 상상해 봅시다. 오프셋 또는 커서 페이지네이션을 사용하여 이 컬렉션에서 문서를 가져올 수 있습니다.
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
먼저 Appwrite SDK 라이브러리를 가져오고 특정 Appwrite 인스턴스와 특정 프로젝트에 연결하는 인스턴스를 설정합니다. 그런 다음 오프셋 페이지네이션을 사용하여 10개의 문서를 나열하고 게시된 문서만 표시하도록 필터를 설정합니다. 바로 직후, offset 대신 cursor 페이지네이션을 사용하는 것을 제외하고는 정확히 동일한 문서 나열 쿼리를 작성합니다.
📊 벤치마크
우리는 이 기사에서 실제 수치를 제공하지 않고 성능이라는 단어를 꽤 자주 사용했으므로 함께 벤치마크를 만들어 봅시다! 오프셋과 커서 페이지네이션을 모두 지원하는 Appwrite를 백엔드 서버로 사용하고 Node.JS를 사용하여 벤치마크 스크립트를 작성할 것입니다. 타국적으로 Javascript는 꽤 따라하기 쉽습니다.
GitHub 리포지토리에서 전체 소스 코드를 찾을 수 있습니다.
먼저 Appwrite를 설정하고, 사용자를 등록하고, 프로젝트를 만들고, 컬렉션 수준 권한과 읽기 권한이 role:all로 설정된 posts라는 컬렉션을 만듭니다. 이 프로세스에 대한 자세한 내용은 Appwrite 문서를 참조하세요. 이제 Appwrite를 사용할 준비가 되었을 것입니다.
데이터베이스가 비어 있기 때문에 아직 벤치마크를 수행할 수 없습니다! 테이블에 데이터를 채워 봅시다. 다음 스크립트를 사용하여 MariaDB 데이터베이스에 데이터를 로드하고 벤치마크를 준비합니다.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
우리는 스크립트 속도를 높이기 위해 2계층 for 루프를 사용했습니다. 첫 번째 for 루프는 기다려야 하는 쿼리 실행을 생성하고 두 번째 루프는 여러 삽입 요청을 보유하는 긴 쿼리를 생성합니다. 이상적으로는 모든 것을 하나의 요청에 담고 싶지만 MySQL 구성으로 인해 불가능하므로 100개의 요청으로 나눴습니다.
1분도 채 안 되어 100만 개의 문서가 삽입되었으며 벤치마크를 시작할 준비가 되었습니다. 이 데모에는 k6 부하 테스트 라이브러리를 사용할 것입니다.
먼저 잘 알려져 있고 널리 사용되는 오프셋 페이지네이션을 벤치마킹해 보겠습니다. 각 테스트 시나리오에서 데이터 세트의 다른 부분에서 10개의 문서가 있는 페이지를 가져오려고 시도합니다. 오프셋 0에서 시작하여 100k씩 증가하여 오프셋 900k까지 진행합니다. 벤치마크는 가능한 한 정확하게 유지하기 위해 한 번에 하나의 요청만 수행하는 방식으로 작성되었습니다. 또한 동일한 벤치마크를 10번 실행하고 평균 응답 시간을 측정하여 통계적 중요성을 보장합니다. k6의 HTTP 클라이언트를 사용하여 Appwrite의 REST API에 요청을 보냅니다.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
다른 오프셋 구성으로 벤치마크를 실행하고 출력을 CSV 파일에 저장하기 위해 간단한 bash 스크립트를 만들었습니다. 이 스크립트는 매번 다른 오프셋 구성으로 k6를 10번 실행합니다. 출력은 콘솔 출력으로 제공됩니다.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
1분 안에 모든 벤치마크가 완료되었고 각 오프셋 구성에 대한 평균 응답 시간이 제공되었습니다. 결과는 예상대로였지만 전혀 만족스럽지 않았습니다.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
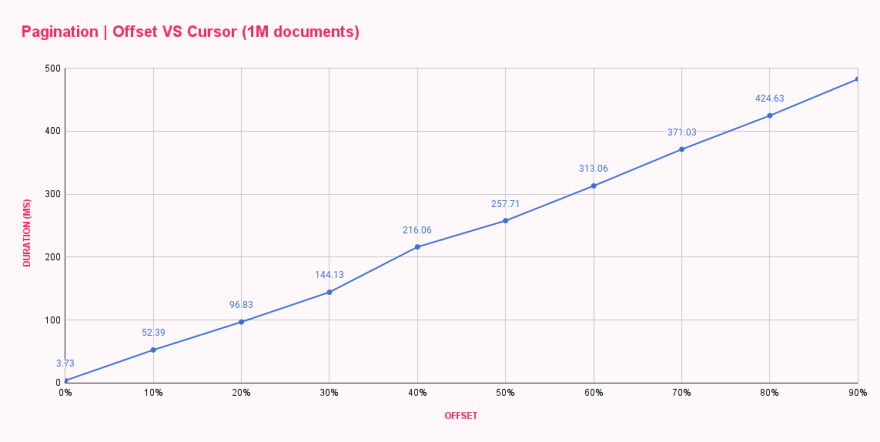
보시다시피 offset 0은 4ms 미만으로 응답하여 꽤 빨랐습니다. 첫 번째 점프는 offset 100k였고 변화는 급격하여 응답 시간이 52ms로 증가했습니다. 오프셋이 증가할 때마다 지속 시간이 늘어나 900k 문서의 오프셋 이후 10개의 문서를 가져오는 데 거의 500ms가 걸렸습니다. 정말 말도 안 됩니다!
이제 스크립트를 업데이트하여 커서 페이지네이션을 사용해 보겠습니다. 스크립트를 업데이트하여 오프셋 대신 커서를 사용하고 bash 스크립트를 업데이트하여 오프셋 번호 대신 커서(문서 ID)를 제공합니다.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
스크립트를 실행한 후 응답 시간에 눈에 띄는 차이가 있었기 때문에 이미 성능 향상이 있었다는 것을 알 수 있었습니다. 두 가지 페이지네이션 방법을 나란히 비교하기 위해 결과를 표에 넣었습니다.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
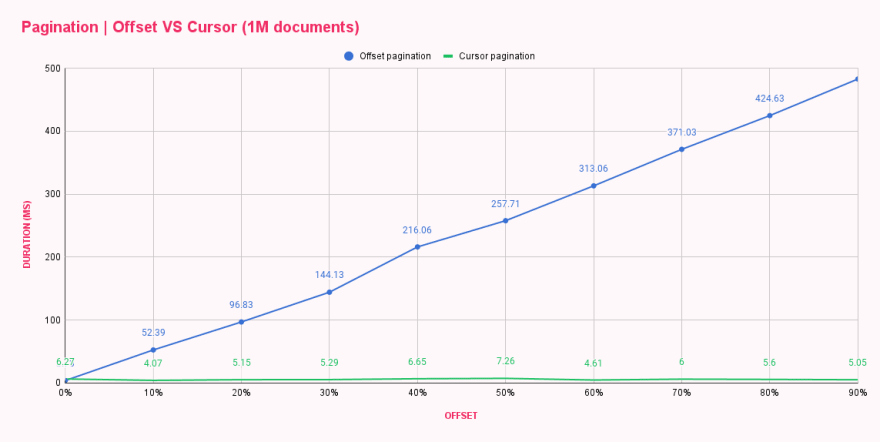
와우! 커서 페이지네이션은 정말 대단합니다! 그래프는 커서 페이지네이션이 오프셋 크기에 상관하지 않으며 모든 쿼리가 첫 번째 또는 마지막 쿼리만큼 성능이 우수함을 보여줍니다. 거대한 목록의 마지막 페이지를 반복적으로 로드하면 얼마나 많은 해를 끼칠 수 있는지 상상할 수 있나요? 😬
자신의 컴퓨터에서 테스트를 실행하는 데 관심이 있다면 전체 소스 코드를 GitHub 리포지토리에서 찾을 수 있습니다. 이 리포지토리에는 전체 설치 및 스크립트 실행 프로세스를 설명하는 README.md가 포함되어 있습니다.
👨🎓 요약
오프셋 페이지네이션은 페이지 번호를 보고 클릭할 수 있는 잘 알려진 페이지네이션 방법을 제공합니다. 이 직관적인 방법은 높은 오프셋에서 끔찍한 성능과 데이터 중복 및 데이터 누락 가능성과 같은 많은 단점을 동반합니다.
커서 페이지네이션은 이러한 모든 문제를 해결하고 빠르며 실시간(자주 변경되는) 데이터를 처리할 수 있는 안정적인 페이지네이션 시스템을 제공합니다. 커서 페이지네이션의 단점은 페이지 번호를 표시하지 않고, 구현하기 복잡하며, 누락된 커서 ID와 같이 극복해야 할 새로운 과제가 있다는 것입니다.
이제 원래 질문으로 돌아가 보겠습니다. 왜 GitHub는 커서 페이지네이션을 사용하지만 Amazon은 오프셋 페이지네이션을 사용하기로 결정했을까요? 성능이 항상 핵심은 아닙니다… 사용자 경험은 비즈니스가 지불해야 하는 서버 수보다 훨씬 더 가치가 있습니다.
저는 Amazon이 UX를 개선하기 때문에 오프셋을 사용하기로 결정했다고 믿지만, 그것은 또 다른 연구 주제입니다. amazon.com을 방문하여 펜을 검색하면 정확히 10,000개의 결과가 있다고 나오지만 처음 7페이지(350개 결과)만 방문할 수 있다는 것을 이미 알 수 있습니다.
첫째, 10k 개 이상의 결과가 있지만 Amazon은 이를 제한합니다. 둘째, 어쨌든 처음 7페이지는 방문할 수 있습니다. 8페이지를 방문하려고 하면 404 오류가 표시됩니다. 보시다시피 Amazon은 오프셋 페이지네이션의 성능을 알고 있지만 사용자 기반이 페이지 번호 보는 것을 선호하기 때문에 유지하기로 결정했습니다. 그들은 몇 가지 제한을 포함해야 했지만, 어쨌든 누가 검색 결과의 100페이지까지 가겠습니까? 🤷
페이지네이션에 대해 읽는 것보다 더 좋은 것이 무엇인지 아십니까? 직접 시도해 보는 것입니다! 직접 경험해 보는 것이 가장 좋으므로 두 가지 방법을 모두 시도해 보시길 권장합니다. Appwrite를 설정하는 데 몇 분도 걸리지 않으며 두 가지 페이지네이션 방법을 모두 사용해 볼 수 있습니다. 질문이 있는 경우 Discord 서버에서 문의할 수도 있습니다.