
Photo by Tobias Fischer on Unsplash
👋 はじめに
データベースは、あらゆるアプリケーションの礎の一つです。アプリケーションが記憶し、後で計算し、他のオンラインユーザーに表示するために必要なすべてのものを保存する場所です。データベースが大きくなり、一度に1,000件の投稿を取得してレンダリングしようとしてアプリケーションが遅延し始めるまでは、すべてが順調です。さて、あなたは賢いエンジニアですよね?あなたはすぐに「もっと見る」ボタンでそれを修正します。数週間後、新しいタイムアウトエラーが発生しました!あなたは Stack Overflow に向かいますが、すぐに Ctrl と V が使いすぎで機能しなくなっていることに気づきます 🤦 他に選択肢がなく、実際にデバッグを開始すると、ユーザーがアプリを開くたびにデータベースが50,000件以上の投稿を返していることに気づきます!どうすればいいでしょうか?

このような恐ろしいシナリオを防ぐために、最初からリスクを認識しておく必要があります。準備の整った開発者は決してリスクを冒す必要がないからです。この記事では、offset(オフセット) と cursor pagination(カーソルページネーション) を使用して、データベース関連のパフォーマンスの問題に対処する準備を整えます。
“予防は治療に勝る。” - ベンジャミン・フランクリン
📚 ページネーションとは?
ページネーションは、数百件以上のレコードを保持するデータセットをクエリする際に採用される戦略です。ページネーションのおかげで、大規模なデータセット を チャンク(またはページ) に分割し、徐々に取得してユーザーに表示することで、データベースへの負荷を軽減できます。ページネーションは、クライアント側とサーバー側の両方で多くのパフォーマンスの問題も解決します!ページネーションがなければ、あなたに送信された最新のメッセージを読むためだけに、チャット履歴全体をロードする必要があります。
最近では、すべてのアプリケーションが 大量のデータ を扱う可能性が高いため、ページネーションはほぼ必須になっています。このデータは、ユーザー生成コンテンツ、管理者や編集者が追加したコンテンツ、自動生成された監査ログなど、あらゆるものが考えられます。リストが数千項目を超えて増えるとすぐに、データベースは各リクエストの解決に時間がかかりすぎ、フロントエンドの速度とアクセシビリティが低下します。ユーザーにとって、彼らの体験はこのようになります。

ページネーションとは何かがわかったところで、実際にどのように使用するのでしょうか?そして、なぜそれが必要なのでしょうか?
🔍 ページネーションの種類
広く使用されている2つのページネーション戦略、offset と cursor があります。深く掘り下げてそれらについてすべてを学ぶ前に、それらを使用しているいくつかのウェブサイトを見てみましょう。
まず、GitHub の Stargazer ページにアクセスして、タブに絶対数ではなく 5,000+ と表示されていることに注目してください。また、標準的なページ番号 の代わりに Previous(前へ) と Next(次へ) ボタンを使用しています。

次に、Amazon の製品リストに切り替えて、正確な結果数 364 と、クリックできる 1 2 3 … 20 の すべてのページ番号 がある 標準的なページネーション に注目してください。

2つのハイテク巨人がどちらのソリューションが優れているかについて合意できなかったことは明らかです!なぜでしょうか?まあ、開発者が嫌う答え、つまり「場合による」を使う必要があります。両方の方法を探求し、それぞれの利点、制限、パフォーマンスへの影響を理解しましょう。
Offset pagination(オフセットページネーション)
ほとんどのウェブサイトは、その シンプルさ とユーザーにとってページネーションがいかに 直感的 であるかという理由から、オフセットページネーションを使用しています。オフセットページネーションを実装するには、通常2つの情報が必要です。
limit- データベースから取得 する行数offset- スキップ する行数。オフセットはページ番号のようなものですが、少し計算が必要です(offset = (page-1) * limit)
データの最初のページを取得するには、limit を 10 に設定し(ページに10個の項目が必要なため)、offset を 0 に設定します(0番目の項目から10個の項目をカウントしたいため)。結果として、10行が取得されます。
2ページ目を取得するには、limit を 10 のままにし(各ページに10行を含めたいため変更しません)、offset を 10 に設定します(10行目以降の結果を返します)。このアプローチを継続することで、エンドユーザーは結果をページ送りし、すべてのコンテンツを見ることができます。
SQL の世界では、このようなクエリは SELECT * FROM posts OFFSET 10 LIMIT 10 と記述されます。
オフセットページネーションを実装している一部のウェブサイトでは、最後のページのページ番号も表示されます。どうやっているのでしょうか?各ページの結果とともに、合計で何行あるかを示す sum 属性も返す傾向があります。limit、sum、少しの計算を使用して、lastPage = ceil(sum / limit) で最後のページ番号を計算できます。
この機能はユーザーにとって便利ですが、開発者はこのタイプのページネーションをスケーリングするのに苦労しています。sum 属性を見ると、データベース内のすべての行を正確な数までカウントするのにかなりの時間がかかることがわかります。さらに、データベースのオフセットは、何行スキップすべきかを知るために行をループする 方法で実装されています。つまり、オフセットが高いほど、データベースクエリにかかる時間が長くなります。
オフセットページネーションのもう一つの欠点は、リアルタイムデータ や 頻繁に変更されるデータ と相性が 良くない ことです。オフセットは 何行スキップしたいか を指定しますが、行の削除 や新しい 行の作成 を考慮 していません。そのようなオフセットは、データの重複 や一部の データの欠落 を表示する結果になる可能性があります。
Cursor pagination(カーソルページネーション)
カーソルはオフセットの後継であり、オフセットページネーションのように 行の相対的な順序 に依存しないため、パフォーマンス、データの欠落、データの重複 というオフセットページネーションのすべての問題を解決します。代わりに、データベースによって 作成および管理 されるインデックスに依存しています。カーソルページネーションを実装するには、以下の情報が必要です。
limit- 前と同じく、1ページに表示したい行数cursor- リスト内の 参照要素 の ID。前のページをクエリしている場合は最初の項目、次のページをクエリしている場合は最後の項目になります。cursorDirection- ユーザーが Next または Previous(その後、またはその前) をクリックしたかどうか
最初のページ をリクエストするときは、何も提供する必要はなく、取得したい行数を示す limit 10 だけで十分です。結果として、10行が得られます。
次のページを取得するには、最後の行 の ID を cursor として使用し、cursorDirection を after に設定します。
同様に、前のページ に移動したい場合は、最初の行 の ID を cursor として使用し、direction を before に設定します。
比較のために、SQL の世界では、クエリを SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC と書くことができます。
offset の代わりに cursor を使用するクエリは、WHERE クエリが 不要な行をスキップ するのに役立つため、パフォーマンスが向上します。一方、OFFSET は それらを反復処理 する必要があり、フルテーブルスキャン になります。ID に適切なインデックスを設定している場合、WHERE を使用して行をスキップすると さらに高速 になります。主キーの場合、インデックスはデフォルトで作成されます。
それだけでなく、行が 挿入 されたり 削除 されたりすることを 心配する必要はもうありません。オフセット10を使用していた場合、現在のページの前に正確に10行が存在すると予想されます。この条件が満たされない場合、クエリは 一貫性のない結果 を返し、データの 重複 や 行の欠落 につながります。これは、現在のページの前の 任意の行が 削除 されたり、新しい行が追加 されたりした場合に発生する可能性があります。カーソルページネーションは、取得した 最後の行のインデックス を使用することでこれを解決し、さらにリクエストしたときにどこから探し始めればよいか正確に知っています。
すべてが良いことばかりではありません。カーソルページネーション をバックエンドで独自に実装する必要がある場合、それは非常に複雑な問題です。カーソルページネーションを実装するには、クエリに WHERE 句と ORDER BY 句が必要です。さらに、必要な条件でフィルタリングするための WHERE 句も必要です。これはすぐに非常に複雑になり、巨大なネストされたクエリになる可能性があります。それに加えて、クエリする必要があるすべての列に対してインデックスを作成する必要もあります。
素晴らしい!カーソルページネーション に切り替えることで、重複 と データの欠落 を排除しました!しかし、まだ1つの問題が残っています。絶対に ユーザーに 増分数値 ID を公開してはならないため(セキュリティ上の理由から)、各 ID のハッシュ化されたバージョン を維持する必要があります。データベースをクエリする必要があるたびに、これらのペアを保持するテーブルを参照して、この文字列 ID を数値 ID に変換します。この 行が見つからない 場合はどうなりますか? Next ボタンをクリックし、最後の行の ID を取得して次のページをリクエストしたが、データベースがその ID を見つけられない場合はどうなりますか?
これは非常にまれな状態であり、カーソルとして使用しようとしている行の ID が削除されたばかりの場合にのみ発生します。この問題は、前の行を試す か、以前のリクエストのデータを再取得 して最後の行を新しい ID で更新することで解決できますが、これらすべてはまったく新しいレベルの複雑さをもたらし、開発者は 再帰 や 適切な状態管理 などの多くの新しい概念を理解する必要があります。幸いなことに、Appwrite などのサービスがこれを処理するため、カーソルページネーションを機能として単純に使用できます。
🚀 Appwrite におけるページネーション
Appwrite はオープンソースの Backend-as-a-Service であり、コアバックエンドのニーズに対応する一連の REST API を提供することで、最新のアプリケーション構築に伴うすべての複雑さを抽象化します。Appwrite は、ユーザー認証と認可、データベース、ファイルストレージ、クラウド関数、Webhook などを処理します!足りないものがあれば、お気に入りのバックエンド言語を使用して Appwrite を拡張できます。
Appwrite Database を使用すると、ユーザー間で共有する必要があるテキストベースのデータを保存できます。Appwrite のデータベースでは、複数のコレクション(テーブル)を作成し、その中に複数のドキュメント(行)を保存できます。各コレクションには、データセットに適切なスキーマを与えるように構成された属性(列)があります。検索クエリのパフォーマンスを高めるためにインデックスを構成することもできます。データを読み取るときは、強力なクエリのホストを使用し、フィルタリング、並べ替え、結果数の制限、およびページネーションを行うことができます。そして、これらすべてがすぐに使用できます!
Appwrite Database をさらに良くしているのは、オフセットページネーションとカーソルページネーションの両方をサポートしている Appwrite のページネーションサポートです!ID が articles のコレクションがあると想像してみましょう。オフセットまたはカーソルページネーションを使用して、このコレクションからドキュメントを取得できます。
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
まず、Appwrite SDK ライブラリをインポートし、特定の Appwrite インスタンスと特定のプロジェクトに接続するインスタンスをセットアップします。次に、オフセットページネーションを使用して10個のドキュメントを一覧表示し、公開されているもののみを表示するフィルターを使用します。直後に、まったく同じドキュメント一覧クエリを記述しますが、今回は offset の代わりに cursor ページネーションを使用します。
📊 ベンチマーク
この記事ではパフォーマンスという言葉を頻繁に使用しましたが、実際の数値は提供していません。そこで、一緒にベンチマークを作成しましょう!Appwrite はオフセットページネーションとカーソルページネーションの両方をサポートしているため、バックエンドサーバーとして Appwrite を使用し、Node.JS を使用してベンチマークスクリプトを記述します。結局のところ、Javascript は非常にわかりやすいです。
完全なソースコードは GitHub リポジトリ にあります。
まず、Appwrite を設定し、ユーザーを登録し、プロジェクトを作成し、コレクションレベルの権限と読み取り権限を role:all に設定した posts というコレクションを作成します。このプロセスの詳細については、Appwrite ドキュメントをご覧ください。これで Appwrite を使用する準備が整ったはずです。
データベースが空なので、まだベンチマークを行うことはできません!テーブルにデータを入力しましょう。次のスクリプトを使用して、MariaDB データベースにデータをロードし、ベンチマークの準備をします。
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
スクリプトの速度を上げるために、2層の for ループを使用しました。最初の for ループは待機する必要があるクエリ実行を作成し、2番目のループは複数の挿入リクエストを保持する長いクエリを作成します。理想的には、すべてを1つのリクエストに入れたいところですが、MySQL の構成上不可能なため、100回のリクエストに分割しました。
1分未満で 100万件のドキュメント が挿入され、ベンチマークを開始する準備が整いました。このデモには k6 負荷テストライブラリを使用します。
まず、よく知られており広く使用されている オフセットページネーション のベンチマークを行いましょう。各テストシナリオでは、データセットのさまざまな部分から 10個のドキュメントを含むページを取得 しようとします。オフセット0から開始し、100kずつ増やしてオフセット900kまで行います。ベンチマークは、可能な限り正確に保つために、一度に1つのリクエストのみを行うように記述されています。また、同じベンチマークを10回実行し、平均応答時間を測定して統計的有意性を確保します。k6 の HTTP クライアントを使用して、Appwrite の REST API にリクエストを送信します。
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
さまざまなオフセット構成でベンチマークを実行し、出力を CSV ファイルに保存するために、単純な bash スクリプトを作成しました。このスクリプトは k6 を10回実行し、毎回異なるオフセット構成 を使用します。出力はコンソール出力として提供されます。
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
1分以内にすべてのベンチマークが終了し、各オフセット構成の 平均応答時間 が得られました。結果は予想通りでしたが、まったく満足のいくものではありませんでした。
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
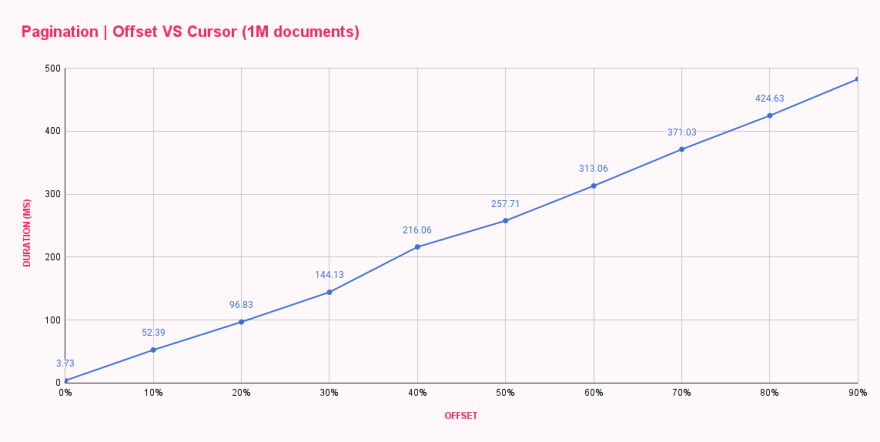
ご覧のとおり、offset 0 は非常に高速で、4ms 未満で応答しました。最初のジャンプは offset 100k で、変化は劇的で、応答時間は 52ms に増加しました。オフセットが増えるたびに所要時間が増加し、900kドキュメントのオフセット後に10個のドキュメントを取得するのにほぼ 500ms かかりました。これはクレイジーです!
次に、スクリプトを更新して カーソルページネーション を使用するようにしましょう。スクリプトを更新して オフセットの代わりにカーソル を使用し、bash スクリプトを更新してオフセット番号の代わりにカーソル(ドキュメント ID)を提供するようにします。
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
スクリプトを実行すると、応答時間に顕著な違いがあったため、すでにパフォーマンスが向上していることがわかりました。結果を表に入れて、これら2つの方法を並べて比較しました。
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
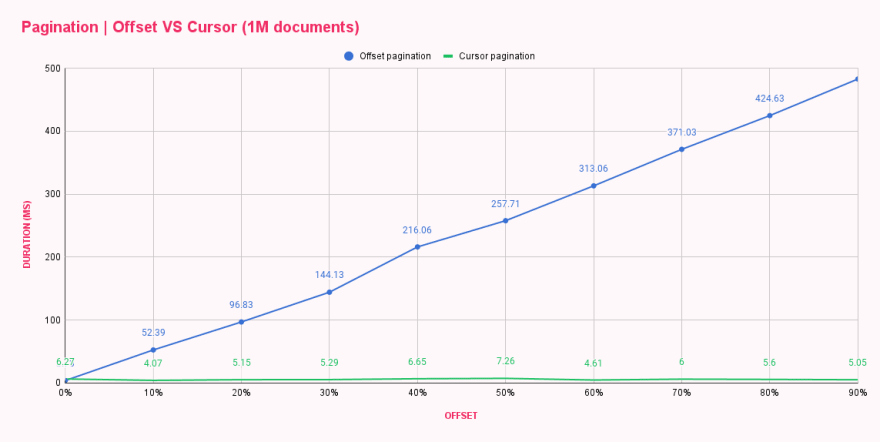
わあ!カーソルページネーション は最高です!グラフは、カーソルページネーションが オフセットサイズ を 気にしない ことを示しており、すべてのクエリが最初または最後のクエリと同じくらいパフォーマンスが高いことを示しています。巨大なリストの最後のページを繰り返しロードすることでどれだけの害が発生するか想像できますか? 😬
自分のマシンでテストを実行することに興味がある場合は、GitHub リポジトリとして完全なソースコードを見つけることができます。リポジトリには、インストールとスクリプトの実行のプロセス全体を説明する README.md が含まれています。
👨🎓 まとめ
オフセットページネーション は、ページ番号が表示され、それをクリックできる、よく知られたページネーション方法を提供します。この直感的な方法には、高いオフセットでのひどいパフォーマンス や、データの重複 や データの欠落 の可能性など、多くの欠点が伴います。
カーソルページネーション はこれらすべての問題を解決し、高速で リアルタイム(頻繁に変更される)データ を処理できる信頼性の高いページネーションシステムをもたらします。カーソルページネーションの欠点は、ページ番号 を 表示しない こと、実装が複雑であること、カーソル ID の欠落などの克服すべき新しい課題があることです。
最初の質問に戻りましょう。なぜ GitHub は カーソルページネーション を使用しているのに、Amazon はオフセットページネーションを採用することにしたのでしょうか?パフォーマンスが常に鍵であるとは限りません… ユーザーエクスペリエンスは、ビジネスが支払わなければならないサーバーの数よりもはるかに価値があります。
Amazon がオフセットを採用したのは、UX を向上させる ためだと信じていますが、それはまた別の研究テーマです。amazon.com にアクセスしてペンを検索すると、正確に 10,000 件の結果があると表示されますが、最初の7ページ(350件の結果)しか表示できないことにすでに気付くことができます。
第一に、結果は10kをはるかに超えていますが、Amazon はそれを制限しています。第二に、とにかく最初の7ページにアクセスできます。8ページ目にアクセスしようとすると、404エラーが表示されます。ご覧のとおり、Amazon は オフセットページネーションのパフォーマンス を認識していますが、ユーザーベースがページ番号を見ることを好むため、それを維持することにしました。彼らは いくつかの制限を含める 必要がありましたが、検索結果の100ページ目に行く人は誰ですか? 🤷
ページネーションについて読むよりも良いことは何か知っていますか?試してみることです!直接体験するのが一番なので、両方の方法を試してみることをお勧めします。Appwrite の設定には数分もかかりません。両方のページネーション方法をいじり始めることができます。ご質問がある場合は、Discord サーバーでお問い合わせください。