
Photo by Tobias Fischer on Unsplash
👋 Introduction
La base de données est l’un des piliers de toute application. C’est là que vous stockez tout ce que votre application doit retenir, calculer plus tard ou afficher à d’autres utilisateurs en ligne. Tout est amusant jusqu’à ce que la base de données grandisse et que votre application commence à ralentir parce que vous essayiez de récupérer et d’afficher 1 000 publications à la fois. Eh bien, vous êtes un ingénieur intelligent, non ? Vous corrigez rapidement cela avec un bouton “Afficher plus”. Quelques semaines plus tard, vous faites face à une nouvelle erreur de Timeout ! Vous vous dirigez vers Stack Overflow mais réalisez rapidement que Ctrl et V ont cessé de fonctionner en raison d’une utilisation excessive 🤦 Sans plus d’options à votre disposition, vous commencez réellement à déboguer et réalisez que la base de données renvoie plus de 50 000 publications à chaque fois qu’un utilisateur ouvre votre application ! Que faisons-nous maintenant ?

Pour éviter ces scénarios horribles, nous devons être conscients des risques dès le début, car un développeur bien préparé n’aura jamais à prendre de risques. Cet article vous préparera à combattre les problèmes de performance liés à la base de données en utilisant offset et cursor pagination.
“Mieux vaut prévenir que guérir.” - Benjamin Franklin
📚 Qu’est-ce que la pagination ?
La pagination est une stratégie employée lors de la requête de tout ensemble de données contenant plus de quelques centaines d’enregistrements. Grâce à la pagination, nous pouvons diviser notre grand ensemble de données en morceaux (ou pages) que nous pouvons récupérer progressivement et afficher à l’utilisateur, réduisant ainsi la charge sur la base de données. La pagination résout également de nombreux problèmes de performance tant côté client que côté serveur ! Sans pagination, vous devriez charger tout l’historique de chat juste pour lire le dernier message qui vous a été envoyé.
De nos jours, la pagination est presque devenue une nécessité car chaque application est très susceptible de traiter de grandes quantités de données. Ces données peuvent être n’importe quoi, du contenu généré par l’utilisateur, du contenu ajouté par des administrateurs ou des éditeurs, ou des audits et des journaux générés automatiquement. Dès que votre liste dépasse quelques milliers d’éléments, votre base de données prendra trop de temps pour résoudre chaque demande et la vitesse et l’accessibilité de votre front-end seront affectées. Quant à vos utilisateurs, leur expérience ressemblera à quelque chose comme ça.

Maintenant que nous savons ce qu’est la pagination, comment l’utilisons-nous réellement ? Et pourquoi est-elle nécessaire ?
🔍 Types de pagination
Il existe deux stratégies de pagination largement utilisées - offset et cursor. Avant de creuser plus profondément et de tout apprendre à leur sujet, examinons quelques sites Web qui les utilisent.
Tout d’abord, visitons la page Stargazer de GitHub et remarquons comment l’onglet indique 5,000+ et non un nombre absolu ? De plus, au lieu des numéros de page standard, ils utilisent les boutons Previous (Précédent) et Next (Suivant).

Maintenant, passons à la liste de produits d’Amazon et remarquons le nombre exact de résultats 364, et la pagination standard avec tous les numéros de page sur lesquels vous pouvez cliquer 1 2 3 … 20.

Il est assez clair que deux géants de la technologie n’ont pas pu s’entendre sur la meilleure solution ! Pourquoi ? Eh bien, nous devrons utiliser une réponse que les développeurs détestent : Ça dépend. Explorons les deux méthodes pour comprendre leurs avantages, leurs limites et leurs implications en termes de performances.
Offset pagination (Pagination par décalage)
La plupart des sites Web utilisent la pagination par décalage en raison de sa simplicité et de la nature intuitive de la pagination pour les utilisateurs. Pour implémenter la pagination par décalage, nous aurons généralement besoin de deux informations :
limit- Nombre de lignes à récupérer de la base de donnéesoffset- Nombre de lignes à ignorer. Le décalage est comme un numéro de page, mais avec un peu de mathématiques autour(offset = (page-1) * limit)
Pour obtenir la première page de nos données, nous définissons limit à 10 (parce que nous voulons 10 éléments sur la page) et offset à 0 (parce que nous voulons commencer à compter 10 éléments à partir du 0ème élément). En résultat, nous obtiendrons dix lignes.
Pour obtenir la deuxième page, nous maintenons limit à 10 (cela ne change pas car nous voulons que chaque page contienne 10 lignes) et définissons offset à 10 (renvoie les résultats à partir de la 10ème ligne). Nous continuons cette approche, permettant ainsi à l’utilisateur final de paginer à travers les résultats et de voir tout son contenu.
Dans le monde SQL, une telle requête s’écrirait comme SELECT * FROM posts OFFSET 10 LIMIT 10.
Certains sites Web implémentant la pagination par décalage affichent également le numéro de page de la dernière page. Comment font-ils cela ? En plus des résultats pour chaque page, ils ont également tendance à renvoyer un attribut sum qui vous indique combien de lignes il y a au total. En utilisant limit, sum et un peu de mathématiques, vous pouvez calculer le dernier numéro de page en utilisant lastPage = ceil(sum / limit)
Aussi pratique que cette fonctionnalité soit pour l’utilisateur, les développeurs ont du mal à faire évoluer ce type de pagination. En regardant l’attribut sum, nous pouvons déjà voir qu’il peut prendre un certain temps pour compter toutes les lignes d’une base de données jusqu’au nombre exact. En plus de cela, le décalage dans la base de données est implémenté de manière à ce qu’il itère à travers les lignes pour savoir combien doivent être ignorées. Cela signifie que plus notre décalage est élevé, plus notre requête de base de données prendra du temps.
Un autre inconvénient de la pagination par décalage est qu’elle ne fonctionne PAS bien avec les données en temps réel ou les données changeant fréquemment. Le décalage indique combien de lignes nous voulons ignorer mais ne tient PAS compte de la suppression de lignes ou de la création de nouvelles lignes. Un tel décalage peut entraîner l’affichage de données dupliquées ou de certaines données manquantes.
Cursor pagination (Pagination par curseur)
Les curseurs sont les successeurs de l’offset, car ils résolvent tous les problèmes que la pagination par décalage a - performances, données manquantes et duplication de données car elle ne s’appuie pas sur l’ordre relatif des lignes comme dans le cas de la pagination par décalage. Au lieu de cela, elle s’appuie sur un index créé et géré par la base de données. Pour implémenter la pagination par curseur, nous aurons besoin des informations suivantes :
limit- Comme tout à l’heure, nombre de lignes que nous voulons afficher sur une seule pagecursor- ID d’un élément de référence dans la liste. Cela peut être lepremier élémentsi vous demandez lapage précédenteet ledernier élémentsi vous demandez lapage suivante.cursorDirection- Si l’utilisateur a cliqué sur Next ou Previous (après ou avant)
Lors de la demande de la première page, nous n’avons besoin de rien fournir, juste limit 10, indiquant combien de lignes nous voulons obtenir. En résultat, nous obtenons nos dix lignes.
Pour obtenir la page suivante, nous utilisons l’ID de la dernière ligne comme cursor et définissons cursorDirection sur after.
De même, si nous voulons aller à la page précédente, nous utilisons l’ID de la première ligne comme cursor et définissons direction sur before.
Pour comparer, dans le monde SQL, nous pourrions écrire notre requête comme SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC.
Les requêtes qui utilisent un curseur au lieu d’un décalage sont plus performantes car la requête WHERE aide à ignorer les lignes indésirables, tandis que OFFSET doit itérer sur elles, résultant en un scan complet de la table (full-table scan). Ignorer les lignes en utilisant WHERE peut être encore plus rapide si vous configurez des index appropriés sur vos ID. L’index est créé par défaut dans le cas de votre clé primaire.
Non seulement cela, vous n’avez plus besoin de vous soucier des lignes insérées ou supprimées. Si vous utilisiez un décalage de 10, vous vous attendriez à ce qu’exactement 10 lignes soient présentes avant votre page actuelle. Si cette condition n’était pas remplie, votre requête renverra des résultats incohérents conduisant à une duplication de données et même à des lignes manquantes. Cela peut se produire si l’une des lignes devant votre page actuelle a été supprimée ou si de nouvelles lignes ont été ajoutées. La pagination par curseur résout ce problème en utilisant l’index de la dernière ligne que vous avez récupérée et elle sait exactement où commencer à chercher, lorsque vous en demandez plus.
Tout n’est pas rose. La pagination par curseur est un problème vraiment complexe si vous devez l’implémenter vous-même sur le backend. Pour implémenter la pagination par curseur, vous aurez besoin de clauses WHERE et ORDER BY dans votre requête. De plus, vous aurez également besoin de clauses WHERE pour filtrer selon vos conditions requises. Cela peut devenir assez complexe très rapidement et vous pourriez vous retrouver avec une énorme requête imbriquée. En plus de cela, vous devrez également créer des index pour toutes les colonnes que vous devez interroger.
Génial ! Nous nous sommes débarrassés des doublons et des données manquantes en passant à la pagination par curseur ! Mais il nous reste encore un problème. Puisque vous ne DEVEZ PAS exposer des ID numériques incrémentiels à l’utilisateur (pour des raisons de sécurité), vous devez maintenant maintenir une version hachée de chaque ID. Chaque fois que vous devez interroger une base de données, vous convertissez cet ID de chaîne en son ID numérique en regardant une table contenant ces paires. Que se passe-t-il si cette ligne est manquante ? Que se passe-t-il si vous cliquez sur le bouton Suivant, prenez l’ID de la dernière ligne et demandez la page suivante, mais que la base de données ne peut pas trouver l’ID ?
C’est une condition vraiment rare et ne se produit que si l’ID de la ligne que vous êtes sur le point d’utiliser comme curseur vient d’être supprimé. Nous pouvons résoudre ce problème en essayant les lignes précédentes ou en récupérant les données des demandes précédentes pour mettre à jour la dernière ligne avec un nouvel ID, mais tout cela apporte un tout nouveau niveau de complexité, et le développeur doit comprendre un tas de nouveaux concepts, tels que la récursion et la gestion appropriée de l'état. Heureusement, des services comme Appwrite s’occupent de cela, vous pouvez donc simplement utiliser la pagination par curseur comme une fonctionnalité.
🚀 Pagination dans Appwrite
Appwrite est un backend-as-a-service open source qui abstrait toute la complexité impliquée dans la création d’une application moderne en vous fournissant un ensemble d’API REST pour vos besoins de base en matière de backend. Appwrite gère l’authentification et l’autorisation des utilisateurs, les bases de données, le stockage de fichiers, les fonctions cloud, les webhooks et bien plus encore ! S’il manque quelque chose, vous pouvez étendre Appwrite en utilisant votre langage backend préféré.
La base de données Appwrite vous permet de stocker toutes les données textuelles qui doivent être partagées entre vos utilisateurs. La base de données d’Appwrite vous permet de créer plusieurs collections (tables) et d’y stocker plusieurs documents (lignes). Chaque collection a des attributs (colonnes) configurés pour donner à votre ensemble de données un schéma approprié. Vous pouvez également configurer des index pour rendre vos requêtes de recherche plus performantes. Lors de la lecture de vos données, vous pouvez utiliser une multitude de requêtes puissantes, les filtrer, les trier, limiter le nombre de résultats et paginer dessus. Et tout cela est disponible dès la sortie de la boîte !
Ce qui rend la base de données Appwrite encore meilleure est le support de pagination d’Appwrite, car nous prenons en charge à la fois la pagination par décalage et par curseur ! Imaginons que nous avons une collection avec l’ID articles, nous pouvons obtenir des documents de cette collection avec une pagination par décalage ou par curseur :
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
Tout d’abord, nous importons la bibliothèque SDK Appwrite et configurons une instance connectée à une instance Appwrite spécifique et à un projet spécifique. Ensuite, nous listons 10 documents en utilisant la pagination par décalage tout en ayant un filtre pour ne montrer que ceux qui sont publiés. Juste après, nous écrivons exactement la même requête de liste de documents, mais cette fois en utilisant la pagination par curseur au lieu de décalage.
📊 Benchmarks
Nous avons utilisé le mot performance assez souvent dans cet article sans fournir de chiffres réels, alors créons un benchmark ensemble ! Nous utiliserons Appwrite comme notre serveur backend car il prend en charge la pagination par décalage et par curseur et Node.JS pour écrire les scripts de benchmark. Après tout, Javascript est assez facile à suivre.
Vous pouvez trouver le code source complet sous forme de dépôt GitHub.
Tout d’abord, nous configurons Appwrite, enregistrons un utilisateur, créons un projet et créons une collection nommée posts avec une permission au niveau collection et une permission de lecture définie sur role:all. Pour en savoir plus sur ce processus, visitez la documentation d’Appwrite. Nous devrions maintenant avoir Appwrite prêt à être utilisé.
Nous ne pouvons pas encore faire de benchmark, car notre base de données est vide ! Remplissons notre table avec quelques données. Nous utilisons le script suivant pour charger des données dans notre base de données MariadDB et nous préparer pour le benchmark.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
Nous avons utilisé deux couches de boucles for pour augmenter la vitesse du script. La première boucle for crée des exécutions de requête qui doivent être attendues, et la deuxième boucle crée une longue requête contenant plusieurs demandes d’insertion. Idéalement, nous aurions voulu tout dans une seule requête, mais c’est impossible en raison de la configuration MySQL, donc nous l’avons divisée en 100 requêtes.
Nous avons 1 million de documents insérés en moins d’une minute, et nous sommes prêts à commencer nos benchmarks. Nous utiliserons la bibliothèque de test de charge k6 pour cette démo.
Commençons par évaluer la pagination par décalage bien connue et largement utilisée. Au cours de chaque scénario de test, nous essayons de récupérer une page avec 10 documents, à partir de différentes parties de notre ensemble de données. Nous commencerons avec un décalage de 0 et irons jusqu’à un décalage de 900k par incréments de 100k. Le benchmark est écrit de telle manière qu’il ne fait qu’une seule demande à la fois pour rester aussi précis que possible. Nous exécuterons également le même benchmark dix fois et mesurerons les temps de réponse moyens pour garantir la signification statistique. Nous utiliserons le client HTTP de k6 pour faire des demandes à l’API REST d’Appwrite.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
Pour exécuter le benchmark avec différentes configurations de décalage et stocker la sortie dans des fichiers CSV, j’ai créé un script bash simple. Ce script exécute k6 dix fois, avec une configuration de décalage différente à chaque fois. La sortie sera fournie sous forme de sortie console.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
En une minute, tous les benchmarks étaient terminés et me fournissaient le temps de réponse moyen pour chaque configuration de décalage. Les résultats étaient conformes aux attentes mais pas du tout satisfaisants.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
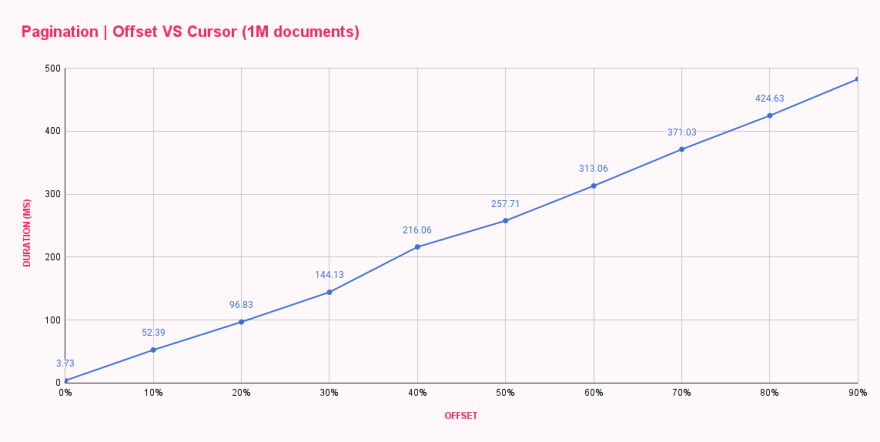
Comme nous pouvons le voir, offset 0 était assez rapide, répondant en moins de 4ms. Notre premier saut a été vers offset 100k, et le changement a été drastique, augmentant les temps de réponse à 52ms. À chaque augmentation du décalage, la durée augmentait, ce qui entraînait près de 500ms pour obtenir dix documents après un décalage de 900k documents. C’est fou !
Maintenant, mettons à jour notre script pour utiliser la pagination par curseur. Nous mettrons à jour notre script pour utiliser le curseur au lieu du décalage et mettrons à jour notre script bash pour fournir le curseur (ID du document) au lieu du numéro de décalage.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
Après avoir exécuté le script, nous pouvions déjà dire qu’il y avait un gain de performances car il y avait des différences notables dans les temps de réponse. Nous avons mis les résultats dans un tableau pour comparer ces deux méthodes de pagination côte à côte.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
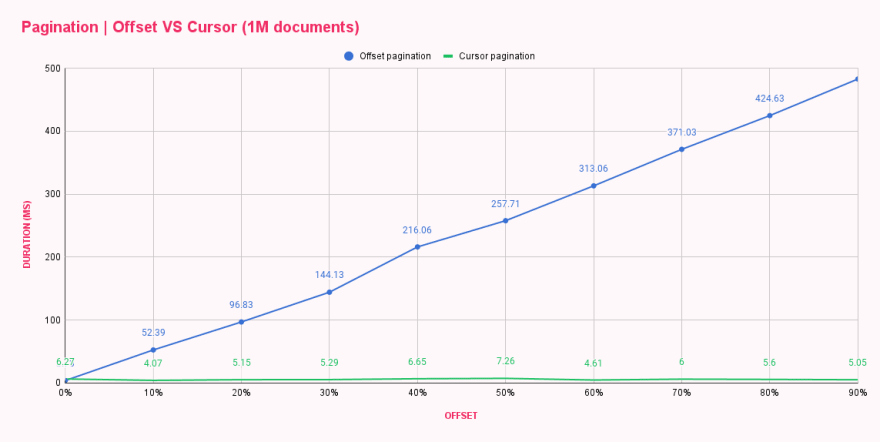
Wow ! La pagination par curseur est cool ! Le graphique montre que la pagination par curseur ne se SOUCIE PAS de la taille du décalage, et chaque requête est aussi performante que la première ou la dernière. Pouvez-vous imaginer combien de dégâts peuvent être causés en chargeant la dernière page d’une liste énorme à plusieurs reprises ? 😬
Si vous êtes intéressé par l’exécution de tests sur votre propre machine, vous pouvez trouver le code source complet sous forme de dépôt GitHub. Le dépôt comprend un README.md expliquant tout le processus d’installation et d’exécution des scripts.
👨🎓 Résumé
La pagination par décalage offre une méthode de pagination bien connue où vous pouvez voir les numéros de page et cliquer dessus. Cette méthode intuitive s’accompagne d’un tas d’inconvénients, tels que des performances terribles avec un décalage élevé et la possibilité de duplication de données et de données manquantes.
La pagination par curseur résout tous ces problèmes et apporte un système de pagination fiable qui est rapide et peut gérer des données en temps réel (changeant fréquemment). L’inconvénient de la pagination par curseur est de NE PAS MONTRER les numéros de page, sa complexité de mise en œuvre et un nouvel ensemble de défis à surmonter, tels que l’absence d’ID de curseur.
Revenons maintenant à notre question initiale, pourquoi GitHub utilise la pagination par curseur, mais Amazon a décidé d’opter pour la pagination par décalage ? La performance n’est pas toujours la clé… L’expérience utilisateur est bien plus précieuse que le nombre de serveurs que votre entreprise doit payer.
Je crois qu’Amazon a décidé d’opter pour le décalage car cela améliore l’UX, mais c’est un sujet pour une autre recherche. Nous pouvons déjà remarquer que si nous visitons amazon.com et recherchons un stylo, il indique qu’il y a exactement 10 000 résultats, mais vous ne pouvez visiter que les sept premières pages (350 résultats).
Premièrement, il y a bien plus que seulement 10k résultats, mais Amazon le limite. Deuxièmement, vous pouvez visiter les sept premières pages de toute façon. Si vous essayez de visiter la page 8, elle affiche une erreur 404. Comme nous pouvons le voir, Amazon est conscient des performances de la pagination par décalage mais a quand même décidé de la conserver car sa base d’utilisateurs préfère voir les numéros de page. Ils ont dû inclure certaines limites, mais qui va à la page 100 des résultats de recherche de toute façon ? 🤷
Savez-vous ce qui est mieux que de lire sur la pagination ? L’essayer ! Je vous encourage à essayer les deux méthodes car il est préférable d’avoir une expérience directe. La configuration d’Appwrite prend moins de quelques minutes et vous pouvez commencer à jouer avec les deux méthodes de pagination. Si vous avez des questions, vous pouvez également nous contacter sur notre serveur Discord.