
Photo by Tobias Fischer on Unsplash
👋 Introducción
La base de datos es una de las piedras angulares de toda aplicación. Es donde almacenas todo lo que tu aplicación necesita recordar, calcular más tarde o mostrar a otros usuarios en línea. Todo es diversión y juegos hasta que la base de datos crece y tu aplicación comienza a retrasarse porque estabas intentando obtener y renderizar 1.000 publicaciones a la vez. Bueno, eres un ingeniero inteligente, ¿verdad? Rápidamente parchas eso con un botón de “Mostrar más”. Unas semanas más tarde, ¡se te presenta un nuevo error de tiempo de espera (Timeout)! Te diriges a Stack Overflow pero rápidamente te das cuenta de que Ctrl y V han dejado de funcionar debido al uso excesivo 🤦 Sin más opciones a tu disposición, ¡realmente comienzas a depurar y te das cuenta de que la base de datos devuelve más de 50.000 publicaciones cada vez que un usuario abre tu aplicación! ¿Qué hacemos ahora?

Para prevenir estos escenarios horribles, debemos ser conscientes de los riesgos desde el principio, porque un desarrollador bien preparado nunca tendrá que arriesgarse. Este artículo te preparará para combatir los problemas de rendimiento relacionados con la base de datos utilizando offset y cursor pagination.
“Una onza de prevención vale una libra de cura.” - Benjamin Franklin
📚 ¿Qué es la paginación?
La paginación es una estrategia empleada cuando se consulta cualquier conjunto de datos que contiene más de unos pocos cientos de registros. Gracias a la paginación, podemos dividir nuestro gran conjunto de datos en fragmentos (o páginas) que podemos obtener y mostrar gradualmente al usuario, reduciendo así la carga en la base de datos. ¡La paginación también resuelve muchos problemas de rendimiento tanto en el lado del cliente como en el del servidor! Sin paginación, tendrías que cargar todo el historial de chat solo para leer el último mensaje que se te envió.
En estos días, la paginación casi se ha convertido en una necesidad ya que es muy probable que cada aplicación maneje grandes cantidades de datos. Estos datos podrían ser cualquier cosa, desde contenido generado por el usuario, contenido agregado por administradores o editores, o auditorías y registros generados automáticamente. Tan pronto como tu lista crezca a más de unos pocos miles de elementos, tu base de datos tardará demasiado en resolver cada solicitud y la velocidad y accesibilidad de tu front-end se verán afectadas. En cuanto a tus usuarios, su experiencia se verá algo así.

Ahora que sabemos qué es la paginación, ¿cómo la usamos realmente? ¿Y por qué es necesaria?
🔍 Tipos de paginación
Hay dos estrategias de paginación que se utilizan ampliamente: offset y cursor. Antes de profundizar y aprender todo sobre ellas, veamos algunos sitios web que las utilizan.
Primero, visitemos la página Stargazer de GitHub y observemos cómo la pestaña dice 5,000+ y no un número absoluto. Además, en lugar de números de página estándar, utilizan botones Previous (Anterior) y Next (Siguiente).

Ahora, cambiemos a la lista de productos de Amazon y observemos la cantidad exacta de resultados 364, y la paginación estándar con todos los números de página en los que puedes hacer clic 1 2 3 … 20.

¡Está muy claro que dos gigantes tecnológicos no pudieron ponerse de acuerdo sobre qué solución es mejor! ¿Por qué? Bueno, tendremos que usar una respuesta que los desarrolladores odian: Porque depende. Exploremos ambos métodos para comprender sus ventajas, limitaciones e implicaciones de rendimiento.
Offset pagination (Paginación por desplazamiento)
La mayoría de los sitios web utilizan la paginación por desplazamiento debido a su simplicidad y lo intuitiva que es la paginación para los usuarios. Para implementar la paginación por desplazamiento, generalmente necesitaremos dos piezas de información:
limit- Número de filas para obtener de la base de datosoffset- Número de filas para omitir. El desplazamiento es como un número de página, pero con un poco de matemáticas a su alrededor(offset = (page-1) * limit)
Para obtener la primera página de nuestros datos, establecemos el limit en 10 (porque queremos 10 elementos en la página) y el offset en 0 (porque queremos comenzar a contar 10 elementos desde el elemento 0). Como resultado, obtendremos diez filas.
Para obtener la segunda página, mantenemos el limit en 10 (esto no cambia ya que queremos que cada página contenga 10 filas) y establecemos el offset en 10 (devolver resultados desde la décima fila en adelante). Continuamos con este enfoque, permitiendo así que el usuario final pagine a través de los resultados y vea todo su contenido.
En el mundo SQL, tal consulta se escribiría como SELECT * FROM posts OFFSET 10 LIMIT 10.
Algunos sitios web que implementan la paginación por desplazamiento también muestran el número de página de la última página. ¿Cómo lo hacen? Junto con los resultados de cada página, también tienden a devolver un atributo sum que te dice cuántas filas hay en total. Usando limit, sum y un poco de matemáticas, puedes calcular el número de la última página usando lastPage = ceil(sum / limit)
Por muy conveniente que sea esta función para el usuario, los desarrolladores luchan por escalar este tipo de paginación. Mirando el atributo sum, ya podemos ver que puede llevar bastante tiempo contar todas las filas en una base de datos hasta el número exacto. Junto a eso, el desplazamiento en las bases de datos se implementa de una manera que itera a través de las filas para saber cuántas deben omitirse. Eso significa que cuanto mayor sea nuestro desplazamiento, más tardará nuestra consulta a la base de datos.
Otra desventaja de la paginación por desplazamiento es que NO funciona bien con datos en tiempo real o datos que cambian a menudo. El desplazamiento dice cuántas filas queremos omitir pero NO tiene en cuenta la eliminación de filas o la creación de nuevas filas. Tal desplazamiento puede resultar en mostrar datos duplicados o algunos datos faltantes.
Cursor pagination (Paginación por cursor)
Los cursores son sucesores de los desplazamientos, ya que resuelven todos los problemas que tiene la paginación por desplazamiento: rendimiento, datos faltantes y duplicación de datos porque no se basa en el orden relativo de las filas como en el caso de la paginación por desplazamiento. En cambio, se basa en un índice creado y administrado por la base de datos. Para implementar la paginación por cursor, necesitaremos la siguiente información:
limit- Igual que antes, cantidad de filas que queremos mostrar en una páginacursor- ID de un elemento de referencia en la lista. Este puede ser elprimer elementosi estás consultando lapágina anteriory elúltimo elementosi consultas lapágina siguiente.cursorDirection- Si el usuario hizo clic en Next o Previous (después o antes)
Al solicitar la primera página, no necesitamos proporcionar nada, solo el limit 10, diciendo cuántas filas queremos obtener. Como resultado, obtenemos nuestras diez filas.
Para obtener la página siguiente, usamos el ID de la última fila como el cursor y establecemos cursorDirection en after.
Del mismo modo, si queremos ir a la página anterior, usamos el ID de la primera fila como cursor y establecemos direction en before.
Para comparar, en el mundo SQL, podríamos escribir nuestra consulta como SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC.
Las consultas que usan un cursor en lugar de offset tienen un mayor rendimiento porque la consulta WHERE ayuda a omitir filas no deseadas, mientras que OFFSET necesita iterar sobre ellas, lo que resulta en un escaneo completo de la tabla (full-table scan). Omitir filas usando WHERE puede ser aún más rápido si configuras índices adecuados en tus ID. El índice se crea por defecto en el caso de tu clave primaria.
No solo eso, ya no necesitas preocuparte por las filas que se insertan o eliminan. Si estuvieras usando un desplazamiento de 10, esperarías que exactamente 10 filas estuvieran presentes antes de tu página actual. Si esta condición no se cumpliera, tu consulta devolverá resultados inconsistentes que conducen a la duplicación de datos e incluso a filas faltantes. Esto puede suceder si alguna de las filas delante de tu página actual fue eliminada o se agregaron nuevas filas. La paginación por cursor resuelve esto usando el índice de la última fila que obtuviste y sabe exactamente dónde comenzar a buscar, cuando solicitas más.
No todo es color de rosa. La paginación por cursor es un problema realmente complejo si necesitas implementarlo en el backend por tu cuenta. Para implementar la paginación por cursor, necesitarás cláusulas WHERE y ORDER BY en tu consulta. Además, también necesitarás cláusulas WHERE para filtrar por tus condiciones requeridas. Esto puede volverse bastante complejo muy rápidamente y podrías terminar con una enorme consulta anidada. Junto a eso, también necesitarás crear índices para todas las columnas que necesitas consultar.
¡Genial! ¡Nos deshicimos de los duplicados y los datos faltantes cambiando a la paginación por cursor! Pero todavía nos queda un problema. Dado que NO DEBES exponer ID numéricos incrementales al usuario (por razones de seguridad), ahora debes mantener una versión hash de cada ID. Siempre que necesites consultar una base de datos, conviertes este ID de cadena a su ID numérico mirando una tabla que contiene estos pares. ¿Qué pasa si esta fila falta? ¿Qué pasa si haces clic en el botón Next, tomas el ID de la última fila y solicitas la página siguiente, pero la base de datos no puede encontrar el ID?
Esta es una condición realmente rara y solo ocurre si el ID de la fila que estás a punto de usar como cursor acaba de ser eliminado. Podemos resolver este problema intentando filas anteriores o volviendo a obtener datos de solicitudes anteriores para actualizar la última fila con un nuevo ID, pero todo eso trae un nivel completamente nuevo de complejidad, y el desarrollador necesita comprender un montón de conceptos nuevos, como recursividad y gestión adecuada del estado. Afortunadamente, servicios como Appwrite se encargan de eso, por lo que simplemente puedes usar la paginación por cursor como una característica.
🚀 Paginación en Appwrite
Appwrite es un backend-as-a-service de código abierto que abstrae toda la complejidad involucrada en la creación de una aplicación moderna al proporcionarte un conjunto de API REST para tus necesidades principales de backend. ¡Appwrite maneja la autenticación y autorización de usuarios, bases de datos, almacenamiento de archivos, funciones en la nube, webhooks y mucho más! Si falta algo, puedes extender Appwrite usando tu lenguaje de backend favorito.
Appwrite Database te permite almacenar cualquier dato basado en texto que deba compartirse entre tus usuarios. La base de datos de Appwrite te permite crear múltiples colecciones (tablas) y almacenar múltiples documentos (filas) en ella. Cada colección tiene atributos (columnas) configurados para darle a tu conjunto de datos un esquema adecuado. También puedes configurar índices para hacer que tus consultas de búsqueda tengan un mayor rendimiento. Al leer tus datos, puedes usar una gran cantidad de consultas poderosas, filtrarlas, ordenarlas, limitar la cantidad de resultados y paginar sobre ellas. ¡Y todo esto viene listo para usar!
Lo que hace que Appwrite Database sea aún mejor es el soporte de paginación de Appwrite, ¡ya que admitimos tanto la paginación por desplazamiento como la paginación por cursor! Imaginemos que tenemos una colección con el ID articles, podemos obtener documentos de esta colección con paginación por desplazamiento o por cursor:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
Primero, importamos la biblioteca Appwrite SDK y configuramos una instancia que se conecta a una instancia específica de Appwrite y a un proyecto específico. Luego, enumeramos 10 documentos usando la paginación por desplazamiento mientras tenemos un filtro para mostrar solo aquellos que están publicados. Justo después, escribimos exactamente la misma consulta de lista de documentos, pero esta vez usando la paginación por cursor en lugar de offset.
📊 Puntos de referencia (Benchmarks)
Hemos usado la palabra rendimiento con bastante frecuencia en este artículo sin proporcionar números reales, ¡así que creemos un punto de referencia juntos! Usaremos Appwrite como nuestro servidor backend porque admite paginación por desplazamiento y por cursor y Node.JS para escribir los scripts de referencia. Después de todo, Javascript es bastante fácil de seguir.
Puedes encontrar el código fuente completo como repositorio de GitHub.
Primero, configuramos Appwrite, registramos un usuario, creamos un proyecto y creamos una colección llamada posts con permiso de nivel de colección y permiso de lectura establecido en role:all. Para obtener más información sobre este proceso, visita la documentación de Appwrite. Ahora deberíamos tener Appwrite listo para ser utilizado.
¡No podemos hacer un punto de referencia todavía, porque nuestra base de datos está vacía! Llenemos nuestras tablas con algunos datos. Usamos el siguiente script para cargar datos en nuestra base de datos MariadDB y prepararnos para el punto de referencia.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
Usamos dos capas de bucles for para aumentar la velocidad del script. El primer bucle for crea ejecuciones de consultas que deben esperarse, y el segundo bucle crea una consulta larga que contiene múltiples solicitudes de inserción. Idealmente, querríamos todo en una sola solicitud, pero eso es imposible debido a la configuración de MySQL, por lo que lo dividimos en 100 solicitudes.
Tenemos 1 millón de documentos insertados en menos de un minuto, y estamos listos para comenzar nuestros puntos de referencia. Usaremos la biblioteca de pruebas de carga k6 para esta demostración.
Primero hagamos un punto de referencia de la paginación por desplazamiento bien conocida y ampliamente utilizada. Durante cada escenario de prueba, intentamos obtener una página con 10 documentos, de diferentes partes de nuestro conjunto de datos. Comenzaremos con el desplazamiento 0 e iremos hasta un desplazamiento de 900k en incrementos de 100k. El punto de referencia está escrito de tal manera que realiza solo una solicitud a la vez para mantenerlo lo más preciso posible. También ejecutaremos el mismo punto de referencia diez veces y mediremos los tiempos de respuesta promedio para garantizar la significancia estadística. Usaremos el cliente HTTP de k6 para realizar solicitudes a la API REST de Appwrite.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
Para ejecutar el punto de referencia con diferentes configuraciones de desplazamiento y almacenar la salida en archivos CSV, creé un script bash simple. Este script ejecuta k6 diez veces, con una configuración de desplazamiento diferente cada vez. La salida se proporcionará como salida de consola.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
En un minuto, todos los puntos de referencia terminaron y me proporcionaron el tiempo de respuesta promedio para cada configuración de desplazamiento. Los resultados fueron los esperados pero no satisfactorios en absoluto.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
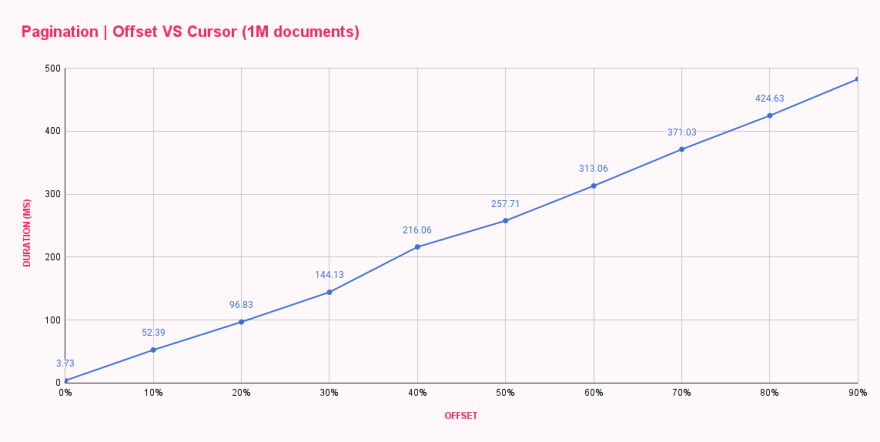
Como podemos ver, offset 0 fue bastante rápido, respondiendo en menos de 4ms. Nuestro primer salto fue a offset 100k, y el cambio fue drástico, aumentando los tiempos de respuesta a 52ms. Con cada aumento en el desplazamiento, la duración aumentó, lo que resultó en casi 500ms para obtener diez documentos después de un desplazamiento de 900k documentos. ¡Eso es una locura!
Ahora actualicemos nuestro script para usar la paginación por cursor. Actualizaremos nuestro script para usar un cursor en lugar de un desplazamiento y actualizaremos nuestro script bash para proporcionar un cursor (ID de documento) en lugar de un número de desplazamiento.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
Después de ejecutar el script, ya podíamos decir que hubo un aumento de rendimiento ya que hubo diferencias notables en los tiempos de respuesta. Hemos puesto los resultados en una tabla para comparar estos dos métodos de paginación uno al lado del otro.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
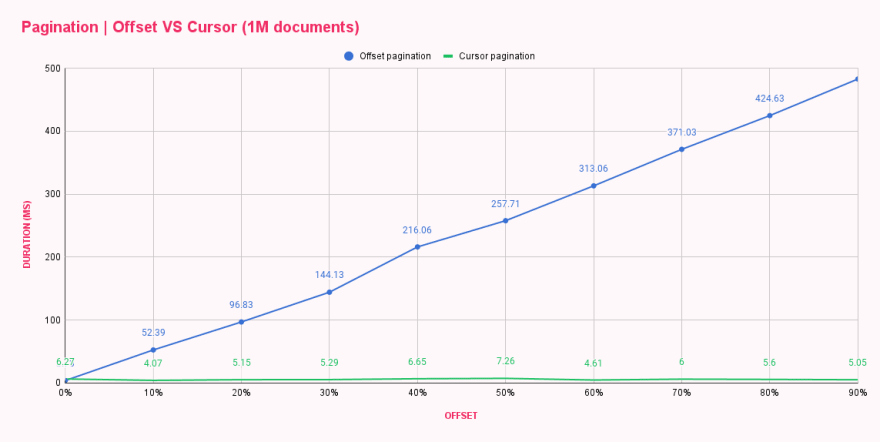
¡Guau! ¡La paginación por cursor es genial! El gráfico muestra que a la paginación por cursor NO LE IMPORTA el tamaño del desplazamiento, y cada consulta es tan eficiente como la primera o la última. ¿Te imaginas cuánto daño se puede hacer cargando la última página de una lista enorme repetidamente? 😬
Si estás interesado en ejecutar pruebas en tu propia máquina, puedes encontrar el código fuente completo como repositorio de GitHub. El repositorio incluye un README.md que explica todo el proceso de instalación y ejecución de scripts.
👨🎓 Resumen
La paginación por desplazamiento ofrece un método de paginación bien conocido donde puedes ver los números de página y hacer clic en ellos. Este método intuitivo viene con un montón de desventajas, como un rendimiento terrible con desplazamientos altos y la posibilidad de duplicación de datos y datos faltantes.
La paginación por cursor resuelve todos estos problemas y trae un sistema de paginación confiable que es rápido y puede manejar datos en tiempo real (que cambian a menudo). La desventaja de la paginación por cursor es NO MOSTRAR números de página, su complejidad de implementación y un nuevo conjunto de desafíos que superar, como la falta de ID de cursor.
Ahora volvamos a nuestra pregunta original, ¿por qué GitHub usa paginación por cursor, pero Amazon decidió optar por la paginación por desplazamiento? El rendimiento no siempre es la clave… La experiencia del usuario es mucho más valiosa que la cantidad de servidores que tu empresa tiene que pagar.
Creo que Amazon decidió optar por el desplazamiento porque mejora la UX, pero ese es un tema para otra investigación. Ya podemos notar que si visitamos amazon.com y buscamos un bolígrafo, dice que hay exactamente 10 000 resultados, pero solo puedes visitar las primeras siete páginas (350 resultados).
Primero, hay mucho más de solo 10k resultados, pero Amazon lo limita. En segundo lugar, puedes visitar las primeras siete páginas de todos modos. Si intentas visitar la página 8, muestra un error 404. Como podemos ver, Amazon es consciente del rendimiento de la paginación por desplazamiento pero aun así decidió mantenerla porque su base de usuarios prefiere ver números de página. Tuvieron que incluir algunos límites, pero ¿quién va a la página 100 de los resultados de búsqueda de todos modos? 🤷
¿Sabes qué es mejor que leer sobre paginación? ¡Probarlo! Te animo a probar ambos métodos porque es mejor tener experiencia de primera mano. Configurar Appwrite lleva menos de unos minutos y puedes comenzar a jugar con ambos métodos de paginación. Si tienes alguna pregunta, también puedes comunicarte con nosotros en nuestro servidor de Discord.