
Photo by Tobias Fischer on Unsplash
👋 Einführung
Die Datenbank ist einer der Eckpfeiler jeder Anwendung. Hier speichern Sie alles, was Ihre App sich merken, später berechnen oder anderen Online-Nutzern anzeigen muss. Es ist alles eitel Sonnenschein, bis die Datenbank wächst und Ihre Anwendung anfängt zu hängen, weil Sie versucht haben, 1.000 Beiträge auf einmal abzurufen und zu rendern. Nun, Sie sind ein intelligenter Ingenieur, oder? Sie beheben das schnell mit einem “Mehr anzeigen”-Button. Ein paar Wochen später erhalten Sie einen neuen Timeout-Fehler! Sie gehen zu Stack Overflow, stellen aber schnell fest, dass Strg und V aufgrund übermäßiger Nutzung nicht mehr funktionieren 🤦 Da Ihnen keine anderen Optionen mehr zur Verfügung stehen, beginnen Sie tatsächlich mit dem Debuggen und stellen fest, dass die Datenbank jedes Mal, wenn ein Benutzer Ihre App öffnet, über 50.000 Beiträge zurückgibt! Was machen wir jetzt?

Um diese schrecklichen Szenarien zu verhindern, sollten wir uns der Risiken von Anfang an bewusst sein, denn ein gut vorbereiteter Entwickler muss kein Risiko eingehen. Dieser Artikel bereitet Sie darauf vor, datenbankbezogene Leistungsprobleme mit offset und cursor pagination zu bekämpfen.
“Vorsorge ist besser als Nachsorge.” - Benjamin Franklin
📚 Was ist Paginierung?
Paginierung (Pagination) ist eine Strategie, die angewendet wird, wenn ein Datensatz abgefragt wird, der mehr als nur ein paar hundert Datensätze enthält. Dank der Paginierung können wir unseren großen Datensatz in Blöcke (oder Seiten) aufteilen, die wir schrittweise abrufen und dem Benutzer anzeigen können, wodurch die Last auf der Datenbank reduziert wird. Paginierung löst auch viele Leistungsprobleme sowohl auf Client- als auch auf Server-Seite! Ohne Paginierung müssten Sie den gesamten Chatverlauf laden, nur um die letzte an Sie gesendete Nachricht zu lesen.
Heutzutage ist Paginierung fast zu einer Notwendigkeit geworden, da jede Anwendung sehr wahrscheinlich mit großen Datenmengen umgehen wird. Diese Daten können alles sein, von benutzergenerierten Inhalten, von Administratoren oder Redakteuren hinzugefügten Inhalten oder automatisch generierten Audits und Logs. Sobald Ihre Liste auf mehr als ein paar tausend Einträge anwächst, benötigt Ihre Datenbank zu lange, um jede Anfrage zu lösen, und die Geschwindigkeit und Zugänglichkeit Ihres Frontends werden darunter leiden. Was Ihre Benutzer betrifft, wird ihre Erfahrung in etwa so aussehen.

Nachdem wir nun wissen, was Paginierung ist, wie verwenden wir sie tatsächlich? Und warum ist sie notwendig?
🔍 Arten der Paginierung
Es gibt zwei weit verbreitete Paginierungsstrategien – offset und cursor. Bevor wir tiefer eintauchen und alles über sie lernen, schauen wir uns einige Websites an, die sie verwenden.
Besuchen wir zuerst die Stargazer-Seite von GitHub. Fällt Ihnen auf, wie der Tab 5.000+ anzeigt und keine absolute Zahl? Außerdem verwenden sie anstelle von Standard-Seitenzahlen die Schaltflächen Previous (Zurück) und Next (Weiter).

Wechseln wir nun zur Produktliste von Amazon. Beachten Sie die genaue Anzahl der Ergebnisse (364) und die Standard-Paginierung mit allen Seitenzahlen, durch die Sie klicken können (1 2 3 … 20).

Es ist ziemlich klar, dass sich zwei Tech-Giganten nicht darauf einigen konnten, welche Lösung besser ist! Warum? Nun, wir müssen eine Antwort verwenden, die Entwickler hassen: Es kommt darauf an. Lassen Sie uns beide Methoden untersuchen, um ihre Vorteile, Einschränkungen und Auswirkungen auf die Leistung zu verstehen.
Offset pagination (Offset-Paginierung)
Die meisten Websites verwenden Offset-Paginierung aufgrund ihrer Einfachheit und wie intuitiv die Paginierung für Benutzer ist. Um Offset-Paginierung zu implementieren, benötigen wir normalerweise zwei Informationen:
limit- Anzahl der Zeilen, die aus der Datenbank abgerufen werden sollenoffset- Anzahl der zu überspringenden Zeilen. Offset ist wie eine Seitenzahl, aber mit ein wenig Mathematik(offset = (page-1) * limit)
Um die erste Seite unserer Daten zu erhalten, setzen wir limit auf 10 (weil wir 10 Einträge auf der Seite wollen) und offset auf 0 (weil wir anfangen wollen, 10 Einträge ab dem 0. Eintrag zu zählen). Als Ergebnis erhalten wir zehn Zeilen.
Um die zweite Seite zu erhalten, behalten wir limit bei 10 (dies ändert sich nicht, da wir möchten, dass jede Seite 10 Zeilen enthält) und setzen offset auf 10 (gibt Ergebnisse ab der 10. Zeile zurück). Wir setzen diesen Ansatz fort, sodass der Endbenutzer durch die Ergebnisse blättern und seinen gesamten Inhalt sehen kann.
In der SQL-Welt würde eine solche Abfrage als SELECT * FROM posts OFFSET 10 LIMIT 10 geschrieben werden.
Einige Websites, die Offset-Paginierung implementieren, zeigen auch die Seitenzahl der letzten Seite an. Wie machen sie das? Neben den Ergebnissen für jede Seite geben sie in der Regel auch ein sum Attribut zurück, das Ihnen mitteilt, wie viele Zeilen insgesamt vorhanden sind. Mit limit, sum und ein wenig Mathematik können Sie die letzte Seitenzahl mit lastPage = ceil(sum / limit) berechnen.
So bequem diese Funktion für den Benutzer auch ist, Entwickler haben Schwierigkeiten, diese Art der Paginierung zu skalieren. Wenn wir uns das sum Attribut ansehen, können wir bereits erkennen, dass das Zählen aller Zeilen einer Datenbank bis zur genauen Zahl eine ganze Weile dauern kann. Darüber hinaus wird Offset in Datenbanken so implementiert, dass er durch Zeilen iteriert, um zu wissen, wie viele übersprungen werden sollen. Das bedeutet, je höher unser Offset ist, desto länger dauert unsere Datenbankabfrage.
Ein weiterer Nachteil der Offset-Paginierung ist, dass sie NICHT gut mit Echtzeitdaten oder sich häufig ändernden Daten funktioniert. Offset sagt, wie viele Zeilen wir überspringen wollen, berücksichtigt aber NICHT das Löschen von Zeilen oder das Erstellen neuer Zeilen. Ein solcher Versatz kann dazu führen, dass duplizierte Daten oder einige fehlende Daten angezeigt werden.
Cursor pagination (Cursor-Paginierung)
Cursor sind Nachfolger von Offset, da sie alle Probleme lösen, die die Offset-Paginierung hat – Leistung, fehlende Daten und Datenduplizierung, da sie sich nicht auf die relative Reihenfolge der Zeilen stützt, wie es bei der Offset-Paginierung der Fall ist. Stattdessen stützt sie sich auf einen erstellten Index, der von der Datenbank verwaltet wird. Um Cursor-Paginierung zu implementieren, benötigen wir folgende Informationen:
limit- Wie zuvor, Anzahl der Zeilen, die wir auf einer Seite anzeigen möchtencursor- ID eines Referenzelements in der Liste. Dies kann daserste Elementsein, wenn Sie dievorherige Seiteabfragen, und dasletzte Element, wenn Sie dienächste Seiteabfragen.cursorDirection- Ob der Benutzer auf Next oder Previous (danach oder davor) geklickt hat
Wenn wir die erste Seite anfordern, müssen wir nichts angeben, nur limit 10, was besagt, wie viele Zeilen wir abrufen möchten. Als Ergebnis erhalten wir unsere zehn Zeilen.
Um die nächste Seite zu erhalten, verwenden wir die ID der letzten Zeile als cursor und setzen cursorDirection auf after.
Ebenso, wenn wir zur vorherigen Seite gehen wollen, verwenden wir die ID der ersten Zeile als cursor und setzen direction auf before.
Zum Vergleich, in der SQL-Welt könnten wir unsere Abfrage als SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC schreiben.
Abfragen, die einen Cursor anstelle von Offset verwenden, sind leistungsfähiger, da die WHERE-Abfrage hilft, unerwünschte Zeilen zu überspringen, während OFFSET über sie iterieren muss, was zu einem Full-Table-Scan führt. Das Überspringen von Zeilen mit WHERE kann noch schneller sein, wenn Sie geeignete Indizes für Ihre IDs einrichten. Der Index wird im Fall Ihres Primärschlüssels standardmäßig erstellt.
Nicht nur das, Sie müssen sich keine Sorgen mehr machen, dass Zeilen eingefügt oder gelöscht werden. Wenn Sie einen Offset von 10 verwenden würden, würden Sie erwarten, dass genau 10 Zeilen vor Ihrer aktuellen Seite vorhanden sind. Wenn diese Bedingung nicht erfüllt ist, gibt unsere Abfrage inkonsistente Ergebnisse zurück, die zu Datenduplizierung und sogar zu fehlenden Zeilen führen. Dies kann passieren, wenn eine der Zeilen vor Ihrer aktuellen Seite gelöscht wurde oder neue Zeilen hinzugefügt wurden. Cursor-Paginierung löst dieses Problem, indem sie den Index der letzten Zeile verwendet, die Sie abgerufen haben, und sie weiß genau, wo sie anfangen soll zu suchen, wenn Sie mehr anfordern.
Es ist nicht alles eitel Sonnenschein. Cursor-Paginierung ist ein wirklich komplexes Problem, wenn Sie es selbst im Backend implementieren müssen. Um Cursor-Paginierung zu implementieren, benötigen Sie WHERE- und ORDER BY-Klauseln in Ihrer Abfrage. Darüber hinaus benötigen Sie auch WHERE-Klauseln, um nach Ihren erforderlichen Bedingungen zu filtern. Dies kann sehr schnell ziemlich komplex werden und Sie könnten am Ende eine riesige verschachtelte Abfrage haben. Außerdem müssen Sie auch Indizes für alle Spalten erstellen, die Sie abfragen müssen.
Großartig! Wir sind Duplikate und fehlende Daten losgeworden, indem wir zur Cursor-Paginierung gewechselt haben! Aber wir haben noch ein Problem übrig. Da Sie dem Benutzer (aus Sicherheitsgründen) NICHT inkrementelle numerische IDs preisgeben SOLLTEN, müssen Sie jetzt eine gehashte Version jeder ID verwalten. Wann immer Sie eine Datenbank abfragen müssen, konvertieren Sie diese String-ID in ihre numerische ID, indem Sie in einer Tabelle nachsehen, die diese Paare enthält. Was passiert, wenn diese Zeile fehlt? Was passiert, wenn Sie auf die Schaltfläche “Weiter” klicken, die ID der letzten Zeile nehmen und die nächste Seite anfordern, aber die Datenbank die ID nicht finden kann?
Dies ist eine wirklich seltene Bedingung und tritt nur auf, wenn die ID der Zeile, die Sie als Cursor verwenden möchten, gerade gelöscht wurde. Wir können dieses Problem lösen, indem wir vorherige Zeilen versuchen oder Daten früherer Anfragen erneut abrufen, um die letzte Zeile mit einer neuen ID zu aktualisieren, aber all das bringt eine ganz neue Komplexitätsebene mit sich, und der Entwickler muss eine Menge neuer Konzepte verstehen, wie z. B. Rekursion und ordnungsgemäßes Zustandsmanagement. Glücklicherweise kümmern sich Dienste wie Appwrite darum, sodass Sie die Cursor-Paginierung einfach als Funktion nutzen können.
🚀 Paginierung in Appwrite
Appwrite ist ein Open-Source-Backend-as-a-Service, das die gesamte Komplexität beim Erstellen einer modernen Anwendung abstrahiert, indem es Ihnen eine Reihe von REST-APIs für Ihre Kern-Backend-Anforderungen zur Verfügung stellt. Appwrite kümmert sich um Benutzerauthentifizierung und -autorisierung, Datenbanken, Dateispeicherung, Cloud-Funktionen, Webhooks und vieles mehr! Wenn etwas fehlt, können Sie Appwrite mit Ihrer bevorzugten Backend-Sprache erweitern.
Mit der Appwrite-Datenbank können Sie alle textbasierten Daten speichern, die zwischen Ihren Benutzern geteilt werden müssen. Mit der Appwrite-Datenbank können Sie mehrere Sammlungen (Tabellen) erstellen und mehrere Dokumente (Zeilen) darin speichern. Jede Sammlung verfügt über konfigurierte Attribute (Spalten), um Ihrem Datensatz ein ordnungsgemäßes Schema zu geben. Sie können auch Indizes konfigurieren, um Ihre Suchanfragen leistungsfähiger zu machen. Beim Lesen Ihrer Daten können Sie eine Reihe leistungsstarker Abfragen verwenden, diese filtern, sortieren, die Anzahl der Ergebnisse begrenzen und paginieren. Und all das ist sofort einsatzbereit!
Was die Appwrite-Datenbank noch besser macht, ist die Paginierungsunterstützung von Appwrite, da wir sowohl Offset- als auch Cursor-Paginierung unterstützen! Stellen wir uns vor, wir haben eine Sammlung mit der ID articles. Wir können Dokumente aus dieser Sammlung entweder mit der Offset- oder der Cursor-Paginierung abrufen:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
Zuerst importieren wir die Appwrite SDK-Bibliothek und richten eine Instanz ein, die mit einer bestimmten Appwrite-Instanz und einem bestimmten Projekt verbunden ist. Dann listen wir 10 Dokumente mit Offset-Paginierung auf, während wir einen Filter haben, um nur die veröffentlichten anzuzeigen. Gleich danach schreiben wir genau dieselbe Dokumentenlistenabfrage, verwenden diesmal jedoch die Cursor- statt der Offset-Paginierung.
📊 Benchmarks
Wir haben das Wort Leistung in diesem Artikel ziemlich oft verwendet, ohne wirkliche Zahlen zu nennen, also lassen Sie uns gemeinsam einen Benchmark erstellen! Wir werden Appwrite als unseren Backend-Server verwenden, da es Offset- und Cursor-Paginierung unterstützt, und Node.JS, um die Benchmark-Skripte zu schreiben. Schließlich ist Javascript ziemlich einfach nachzuvollziehen.
Sie finden den vollständigen Quellcode als GitHub-Repository.
Zuerst richten wir Appwrite ein, registrieren einen Benutzer, erstellen ein Projekt und erstellen eine Sammlung namens posts mit Berechtigung auf Sammlungsebene und Leseberechtigung, die auf role:all gesetzt ist. Um mehr über diesen Prozess zu erfahren, besuchen Sie die Appwrite-Dokumentation. Wir sollten jetzt Appwrite einsatzbereit haben.
Wir können noch keinen Benchmark durchführen, da unsere Datenbank leer ist! Füllen wir unsere Tabelle mit einigen Daten. Wir verwenden das folgende Skript, um Daten in unsere MariadDB-Datenbank zu laden und uns auf den Benchmark vorzubereiten.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
Wir haben zwei Schichten von for-Schleifen verwendet, um die Geschwindigkeit des Skripts zu erhöhen. Die erste for-Schleife erstellt Abfrageausführungen, die abgewartet werden müssen, und die zweite Schleife erstellt eine lange Abfrage, die mehrere Einfüge-Anforderungen enthält. Idealerweise möchten wir alles in einer Anfrage haben, aber das ist aufgrund der MySQL-Konfiguration unmöglich, also haben wir es in 100 Anfragen aufgeteilt.
Wir haben 1 Million Dokumente in weniger als einer Minute eingefügt und sind bereit, unseren Benchmark zu starten. Wir werden die Lasttest-Bibliothek k6 für diese Demo verwenden.
Lassen Sie uns zuerst die bekannte und weit verbreitete Offset-Paginierung benchmarken. In jedem Testszenario versuchen wir, eine Seite mit 10 Dokumenten aus verschiedenen Teilen unseres Datensatzes abzurufen. Wir beginnen mit Offset 0 und gehen in 100k-Schritten bis zu Offset 900k. Der Benchmark ist so geschrieben, dass er jeweils nur eine Anfrage stellt, um so genau wie möglich zu sein. Wir werden denselben Benchmark auch zehnmal ausführen und die durchschnittlichen Antwortzeiten messen, um statistische Signifikanz zu gewährleisten. Wir werden den HTTP-Client von k6 verwenden, um Anfragen an die Appwrite-REST-API zu stellen.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
Um den Benchmark mit unterschiedlichen Offset-Konfigurationen auszuführen und die Ausgabe in CSV-Dateien zu speichern, habe ich ein einfaches Bash-Skript erstellt. Dieses Skript führt k6 zehnmal aus, wobei jedes Mal eine andere Offset-Konfiguration verwendet wird. Die Ausgabe wird als Konsolenausgabe bereitgestellt.
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
Innerhalb einer Minute waren alle Benchmarks abgeschlossen und lieferten mir die durchschnittliche Antwortzeit für jede Offset-Konfiguration. Die Ergebnisse waren wie erwartet, aber überhaupt nicht zufriedenstellend.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
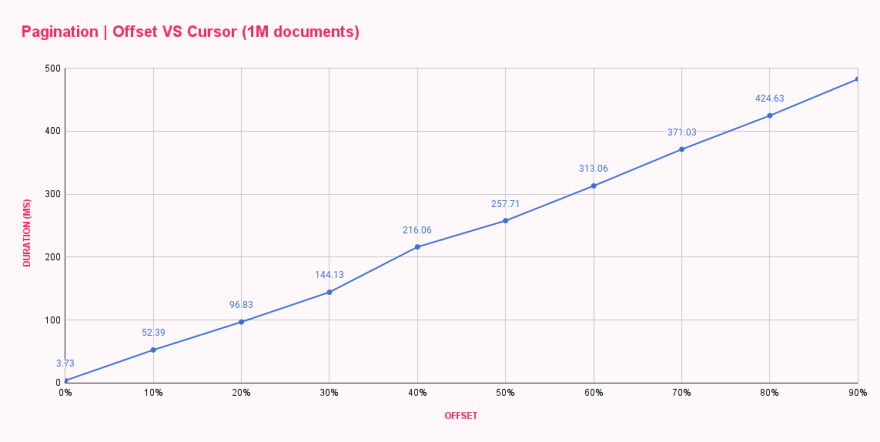
Wie wir sehen können, war Offset 0 ziemlich schnell und antwortete in weniger als 4ms. Unser erster Sprung war zu Offset 100k, und die Änderung war drastisch, da die Antwortzeiten auf 52ms stiegen. Mit jeder Erhöhung des Offsets stieg die Dauer, was zu fast 500ms führte, um zehn Dokumente nach einem Versatz von 900k Dokumenten zu erhalten. Das ist verrückt!
Lassen Sie uns nun unser Skript aktualisieren, um Cursor-Paginierung zu verwenden. Wir werden unser Skript aktualisieren, um die Cursor- anstelle der Offset-Paginierung zu verwenden, und unser Bash-Skript aktualisieren, um den Cursor (Dokument-ID) anstelle der Offset-Nummer bereitzustellen.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
Nach dem Ausführen des Skripts konnten wir bereits feststellen, dass es einen Leistungszuwachs gab, da die Antwortzeiten deutliche Unterschiede aufwiesen. Wir haben die Ergebnisse in eine Tabelle eingefügt, um diese beiden Paginierungsmethoden nebeneinander zu vergleichen.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
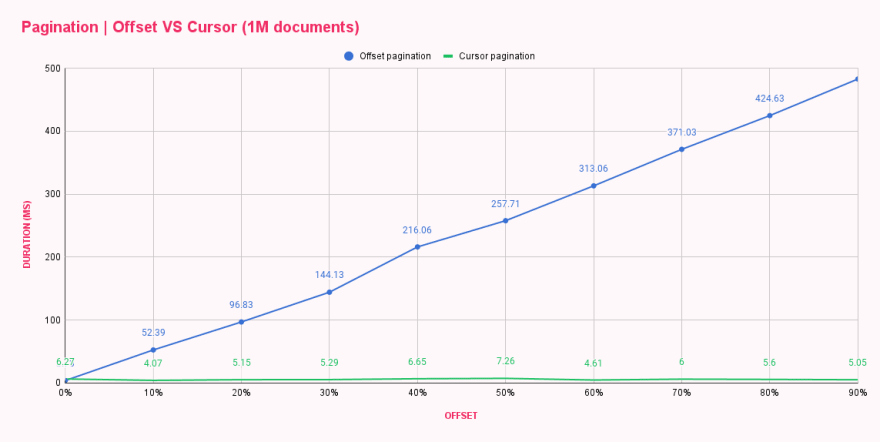
Wow! Cursor-Paginierung ist cool! Die Grafik zeigt, dass sich die Cursor-Paginierung NICHT um die Offset-Größe kümmert und jede Abfrage genauso performant ist wie die erste oder letzte. Können Sie sich vorstellen, wie viel Schaden angerichtet werden kann, wenn die letzte Seite einer riesigen Liste wiederholt geladen wird? 😬
Wenn Sie daran interessiert sind, Tests auf Ihrem eigenen Computer auszuführen, finden Sie den vollständigen Quellcode als GitHub-Repository. Das Repository enthält eine README.md, in der der gesamte Installations- und Ausführungsvorgang der Skripte erklärt wird.
👨🎓 Zusammenfassung
Offset-Paginierung bietet eine bekannte Paginierungsmethode, bei der Sie Seitenzahlen sehen und durchklicken können. Diese intuitive Methode bringt eine Reihe von Nachteilen mit sich, wie z. B. schreckliche Leistung bei hohem Offset und die Möglichkeit von Datenduplizierung und fehlenden Daten.
Cursor-Paginierung löst all diese Probleme und bietet ein zuverlässiges Paginierungssystem, das schnell ist und Echtzeitdaten (sich häufig ändernd) verarbeiten kann. Der Nachteil der Cursor-Paginierung ist, dass Seitenzahlen NICHT ANGEZEIGT werden, ihre Komplexität bei der Implementierung und eine Reihe neuer Herausforderungen, die es zu bewältigen gilt, wie z. B. fehlende Cursor-IDs.
Kommen wir nun zu unserer ursprünglichen Frage zurück: Warum verwendet GitHub Cursor-Paginierung, aber Amazon hat sich für die Offset-Paginierung entschieden? Leistung ist nicht immer der Schlüssel… User Experience (UX) ist viel wertvoller als wie viele Server Ihr Unternehmen bezahlen muss.
Ich glaube, Amazon hat sich für Offset entschieden, weil es die UX verbessert, aber das ist ein Thema für eine andere Untersuchung. Wir können bereits feststellen, dass, wenn wir amazon.com besuchen und nach einem Stift suchen, genau 10.000 Ergebnisse angezeigt werden, Sie aber nur die ersten sieben Seiten (350 Ergebnisse) besuchen können.
Erstens gibt es viel mehr als nur 10k Ergebnisse, aber Amazon begrenzt es. Zweitens können Sie sowieso die ersten sieben Seiten besuchen. Wenn Sie versuchen, Seite 8 zu besuchen, wird ein 404-Fehler angezeigt. Wie wir sehen können, ist sich Amazon der Leistung der Offset-Paginierung bewusst, hat sich aber dennoch entschieden, sie beizubehalten, da ihre Benutzerbasis es vorzieht, Seitenzahlen zu sehen. Sie mussten einige Limits einbauen, aber wer geht schon auf Seite 100 der Suchergebnisse? 🤷
Wissen Sie, was besser ist, als über Paginierung zu lesen? Es auszuprobieren! Ich ermutige Sie, beide Methoden auszuprobieren, da es am besten ist, Erfahrungen aus erster Hand zu sammeln. Das Einrichten von Appwrite dauert weniger als ein paar Minuten, und Sie können anfangen, mit beiden Paginierungsmethoden herumzuspielen. Wenn Sie Fragen haben, können Sie uns auch auf unserem Discord-Server erreichen.