
Photo by Tobias Fischer on Unsplash
👋 前言
資料庫是每個應用程式的基石之一。它是你儲存應用程式所需記憶、稍後運算或顯示給線上其他使用者看的所有內容的地方。在資料庫變大之前,一切都很有趣,直到你的應用程式開始變慢,因為你試圖一次讀取並渲染 1,000 篇文章。好吧,你是個聰明的工程師對吧?你很快地用一個「顯示更多」按鈕修補了這個問題。幾週後,你遇到了一個新的 Timeout 錯誤!你前往 Stack Overflow,但很快發現 Ctrl 和 V 因為過度使用而停止工作了 🤦 在沒有更多選擇的情況下,你實際上開始除錯,並意識到每次使用者打開你的應用程式時,資料庫都會回傳超過 50,000 篇文章!我們現在該怎麼辦?

為了防止這些可怕的情況,我們應該從一開始就意識到風險,因為準備充分的開發人員永遠不需要冒險。這篇文章將準備讓你使用 offset(偏移量) 和 cursor pagination(游標分頁) 來對抗與資料庫相關的效能問題。
“預防勝於治療。” - 本傑明·富蘭克林
📚 什麼是分頁?
分頁是當查詢任何包含超過幾百條記錄的資料集時採用的一種策略。多虧了分頁,我們可以將我們的 大型資料集 分割成我們可以逐步讀取並顯示給使用者的 區塊(或頁面),從而減少資料庫的負載。分頁還解決了客戶端和伺服器端的許多效能問題!如果沒有分頁,你將不得不加載整個聊天記錄,只為了閱讀發送給你的最新訊息。
現今,分頁幾乎已成為必需品,因為每個應用程式都很可能處理大量的資料。這些資料可以是任何東西,從使用者生成的內容、管理員或編輯添加的內容,到自動生成的審計和日誌。一旦你的列表增長到超過幾千個項目,你的資料庫將花費太長時間來解決每個請求,你的前端速度和可訪問性就會受到影響。至於你的使用者,他們的體驗看起來會像這樣。

現在我們知道什麼是分頁了,我們該如何實際使用它?為什麼它是必要的?
🔍 分頁的類型
有兩種被廣泛使用的分頁策略 - offset 和 cursor。在深入研究並學習關於它們的一切之前,讓我們看看一些使用它們的網站。
首先,讓我們訪問 GitHub 的 Stargazer 頁面,注意標籤是怎麼寫 5,000+ 而不是一個絕對數字的?此外,他們使用的是 Previous(上一頁) 和 Next(下一頁) 按鈕,而不是 標準頁碼。

現在,讓我們切換到 Amazon 的產品列表,注意確切的結果數量 364,以及你可以點擊 1 2 3 … 20 的 所有頁碼 的 標準分頁。

很明顯,兩家科技巨頭無法就哪種解決方案更好達成一致!為什麼?好吧,我們需要使用開發人員討厭的一個答案:因為視情況而定。讓我們探索這兩種方法,以了解它們的優點、限制和效能影響。
Offset pagination(偏移量分頁)
大多數網站使用 Offset 分頁,因為它的 簡單性 以及對使用者來說分頁是多麼 直觀。要實作 Offset 分頁,我們通常需要兩條資訊:
limit- 要從資料庫讀取的列數offset- 要跳過的列數。Offset 就像頁碼,但周圍有一些數學運算(offset = (page-1) * limit)
要獲取資料的第一頁,我們將 limit 設定為 10(因為我們希望頁面上有 10 個項目)並將 offset 設定為 0(因為我們希望從第 0 個項目開始計算 10 個項目)。結果,我們將獲得十列。
要獲取第二頁,我們保持 limit 為 10(這不會改變,因為我們希望每一頁包含 10 列)並將 offset 設定為 10(回傳從第 10 列開始的結果)。我們繼續這種方法,從而允許最終使用者對結果進行分頁並查看他們的所有內容。
在 SQL 世界中,這樣的查詢將寫成 SELECT * FROM posts OFFSET 10 LIMIT 10。
一些實作 Offset 分頁的網站也會顯示最後一頁的頁碼。他們是怎麼做到的?除了每一頁的結果外,他們還傾向於回傳一個 sum 屬性,告訴你總共有多少列。使用 limit、sum 和一點數學運算,你可以使用 lastPage = ceil(sum / limit) 計算最後一頁的頁碼。
雖然這個功能對使用者來說很方便,但開發人員在擴展這種類型的分頁時會遇到困難。看著 sum 屬性,我們已經可以看到計算資料庫中所有列的確切數量可能需要相當長的時間。除此之外,資料庫中的 offset 是以一種 迴圈遍歷列以知道應該跳過多少列 的方式實作的。這意味著我們的 offset 越高,我們的資料庫查詢需要的時間就越長。
Offset 分頁的另一個缺點是它不適合 即時資料 或 經常變化的資料。Offset 說明了我們想要跳過多少列,但沒有考慮到 列的刪除 或新的 列被建立。這樣的 offset 可能導致顯示 重複的資料 或某些 資料遺失。
Cursor pagination(游標分頁)
Cursor 是 Offset 的繼承者,因為它們解決了 Offset 分頁所有的問題 - 效能、資料遺失 和 資料重複,因為它不依賴於像 Offset 分頁那樣的 列的相對順序。相反,它依賴於由資料庫 建立和管理 的索引。要實作 Cursor 分頁,我們將需要以下資訊:
limit- 與之前相同,我們希望在一頁上顯示的列數cursor- 列表中參考元素的 ID。如果你正在查詢上一頁,這可以是第一個項目,如果查詢下一頁,這可以是最後一個項目。cursorDirection- 使用者是點擊了 Next 還是 Previous(之後還是之前)
當請求 第一頁 時,我們不需要提供任何東西,只需要 limit 10,說明我們想要獲取多少列。結果,我們得到了我們的十列。
要獲取下一頁,我們使用 最後一列 的 ID 作為 cursor,並將 cursorDirection 設定為 after。
同樣地,如果我們想去 上一頁,我們使用 第一列 的 ID 作為 cursor,並將 direction 設定為 before。
相比之下,在 SQL 世界中,我們可以將查詢寫為 SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC。
使用 cursor 而不是 offset 的查詢效能更好,因為 WHERE 查詢有助於 跳過不需要的列,而 OFFSET 需要 迭代它們,導致 全表掃描。如果你在 ID 上設定適當的索引,使用 WHERE 跳過列會變得 甚至更快。在主鍵的情況下,索引是預設建立的。
不僅如此,你 不再需要擔心 列被 插入 或 刪除。如果你使用的是 10 的 offset,你會期望在你當前頁面之前正好有 10 列。如果這個條件不滿足,你的查詢將回傳 不一致的結果,導致資料 重複 甚至 遺失列。如果任何 在你當前頁面之前的 列被 刪除 或 添加了新列,就會發生這種情況。Cursor 分頁透過使用你讀取的 最後一列的索引 來解決這個問題,它 確切地知道從哪裡開始尋找,當你請求更多時。
這並不全是陽光和彩虹。如果你需要自己在後端實作它,Cursor 分頁 是一個非常複雜的問題。要實作 Cursor 分頁,你將需要在查詢中使用 WHERE 和 ORDER BY 子句。此外,你還需要 WHERE 子句來根據你的需求條件進行過濾。這很快就會變得非常複雜,你可能會得到一個巨大的巢狀查詢。除此之外,你還需要為你需要查詢的所有欄位建立索引。
太棒了!我們透過切換到 Cursor 分頁 擺脫了 重複 和 遺失資料!但我們還剩下一個問題。由於你 不應該 向使用者暴露 遞增的數值 ID(出於安全原因),你現在必須維護 每個 ID 的雜湊版本。每當你需要查詢資料庫時,你可以透過查看保存這些配對的表將此字串 ID 轉換為其數值 ID。如果這個 列遺失 怎麼辦?如果你點擊 Next 按鈕,獲取 最後一列的 ID,並請求下一頁,但資料庫找不到該 ID 怎麼辦?
這是一個非常罕見的情況,只有當你正要用作 cursor 的列的 ID 剛剛被刪除時才會發生。我們可以透過 嘗試之前的列 或 重新讀取早期請求的資料 來用新的 ID 更新最後一列來解決這個問題,但所有這些都帶來了全新的複雜性水平,開發人員需要理解一堆新概念,例如 遞迴 和 適當的狀態管理。值得慶幸的是,像 Appwrite 這樣的服務會處理這個問題,所以你可以簡單地將 Cursor 分頁作為一個功能使用。
🚀 Appwrite 中的分頁
Appwrite 是一個開源的後端即服務 (Backend-as-a-Service),它透過為你的核心後端需求提供一組 REST API,抽象化了建立現代應用程式所涉及的所有複雜性。Appwrite 處理使用者認證和授權、資料庫、檔案儲存、雲端函式、Webhooks 等等!如果有任何遺漏,你可以使用你最喜歡的後端語言擴充 Appwrite。
Appwrite 資料庫讓你儲存任何需要在使用者之間共享的基於文字的資料。Appwrite 的資料庫允許你建立多個集合(表)並在其中儲存多個文件(列)。每個集合都有配置的屬性(欄位),為你的資料集提供適當的架構。你還可以配置索引以使你的搜尋查詢更具效能。讀取資料時,你可以使用大量強大的查詢、過濾它們、排序它們、限制結果數量以及對它們進行分頁。所有這些都是開箱即用的!
讓 Appwrite 資料庫更棒的是 Appwrite 的分頁支援,因為我們同時支援 Offset 和 Cursor 分頁!讓我們想像我們有一個 ID 為 articles 的集合,我們可以使用 Offset 或 Cursor 分頁從這個集合中獲取文件:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
首先,我們引入 Appwrite SDK 函式庫並設定一個連接到特定 Appwrite 實例和特定專案的實例。然後,我們使用 Offset 分頁列出 10 個文件,同時使用過濾器僅顯示已發布的文件。緊接著,我們編寫完全相同的列出文件查詢,但這次使用 cursor 而不是 offset 分頁。
📊 基準測試
我們在這篇文章中經常使用效能這個詞,卻沒有提供任何實際數字,所以讓我們一起建立一個基準測試!我們將使用 Appwrite 作為我們的後端伺服器,因為它同時支援 Offset 和 Cursor 分頁,並使用 Node.JS 編寫基準測試腳本。畢竟,Javascript 非常容易上手。
你可以在 GitHub repository 找到完整的原始碼。
首先,我們設定 Appwrite,註冊一個使用者,建立一個專案並建立一個名為 posts 的集合,集合級別權限和讀取權限設定為 role:all。要了解更多關於此過程的資訊,請訪問 Appwrite 文件。我們現在應該已經準備好使用 Appwrite 了。
我們還不能做基準測試,因為我們的資料庫是空的!讓我們在表中填入一些資料。我們使用以下腳本將資料加載到我們的 MariadDB 資料庫中並為基準測試做準備。
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
我們使用了兩層 for 迴圈來提高腳本的速度。第一個 for 迴圈建立需要等待的查詢執行,第二個迴圈建立一個包含多個插入請求的長查詢。理想情況下,我們希望所有內容都在一個請求中,但由於 MySQL 配置的原因,這是不可能的,所以我們將其分成 100 個請求。
我們在不到一分鐘的時間內插入了 100 萬份文件,我們準備好開始我們的基準測試了。我們將使用 k6 負載測試函式庫進行此演示。
讓我們首先對眾所周知且廣泛使用的 Offset 分頁 進行基準測試。在每個測試場景中,我們嘗試從資料集的不同部分 獲取包含 10 個文件的頁面。我們將從 offset 0 開始,一直到 offset 900k,每次增加 100k。基準測試的編寫方式是,它一次只發出一個請求,以保持盡可能準確。我們還將運行相同的基準測試十次並測量平均回應時間以確保統計顯著性。我們將使用 k6 的 HTTP 客戶端向 Appwrite 的 REST API 發出請求。
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
為了使用不同的 offset 配置運行基準測試並將輸出儲存在 CSV 檔案中,我建立了一個簡單的 bash 腳本。此腳本執行 k6 十次,每次使用不同的 offset 配置。輸出將作為控制台輸出提供。
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
在一分鐘內,所有基準測試都已完成,並為我提供了每個 offset 配置的 平均回應時間。結果如預期,但一點也不令人滿意。
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
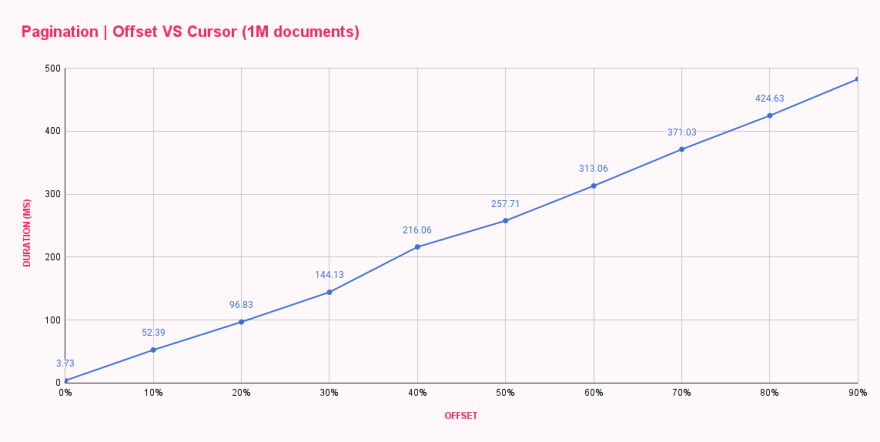
正如我們所見,offset 0 非常快,回應時間不到 4ms。我們的第一個跳轉是到 offset 100k,變化非常劇烈,回應時間增加到 52ms。隨著 offset 的每次增加,持續時間都在上升,導致在 offset 900k 個文件後獲取十個文件幾乎需要 500ms。這太瘋狂了!
現在讓我們更新我們的腳本以使用 Cursor 分頁。我們將更新我們的腳本以使用 cursor 而不是 offset,並更新我們的 bash 腳本以提供 cursor(文件 ID)而不是 offset 數字。
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
運行腳本後,我們可以說已經有了效能提升,因為回應時間有明顯的差異。我們將結果放入表格中,以並排比較這兩種方法。
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
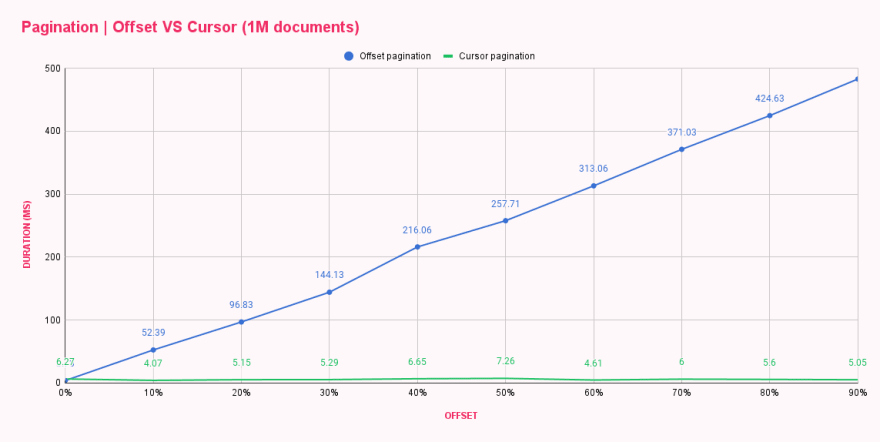
哇!Cursor 分頁 太棒了!圖表顯示 Cursor 分頁 不在乎 offset 大小,每個查詢都與第一個或最後一個查詢一樣高效。你能想像重複加載一個巨大列表的最後一頁會造成多大的傷害嗎? 😬
如果你有興趣在自己的機器上運行測試,你可以在 GitHub repository 找到完整的原始碼。該存儲庫包含解釋整個安裝和運行腳本過程的 README.md。
👨🎓 總結
Offset 分頁 提供了一種眾所周知的分頁方法,你可以看到頁碼並點擊它們。這種直觀的方法伴隨著一堆缺點,例如 高 offsets 時的可怕效能 以及 資料重複 和 資料遺失 的機會。
Cursor 分頁 解決了所有這些問題,並帶來了一個可靠的分頁系統,該系統快速且可以處理 即時(經常變化)資料。Cursor 分頁的缺點是 不顯示 頁碼,實作起來很複雜,以及需要克服的一組新挑戰,例如遺失 cursor ID。
現在讓我們回到我們最初的問題,為什麼 GitHub 使用 Cursor 分頁,但 Amazon 決定使用 Offset 分頁?效能並不總是關鍵… 使用者體驗比你的企業必須支付多少伺服器費用更有價值。
我相信 Amazon 決定使用 offset 是因為它 改善了 UX,但這也是另一個研究主題。我們已經可以注意到,如果我們訪問 amazon.com 並搜尋筆,它說這完全有 10 000 個結果,但你只能訪問前七頁(350 個結果)。
首先,結果遠遠超過 10k,但 Amazon 限制了它。其次,無論如何你都可以訪問前七頁。如果你試圖訪問第 8 頁,它會顯示 404 錯誤。正如我們所見,Amazon 意識到了 Offset 分頁的效能,但仍然決定保留它,因為他們的使用者群偏好查看頁碼。他們不得不 包含一些限制,但是誰會去搜尋結果的第 100 頁呢? 🤷
你知道比閱讀關於分頁的文章更好的是什麼嗎?試試看!我鼓勵你嘗試這兩種方法,因為最好獲得第一手經驗。設定 Appwrite 不需要幾分鐘,你就可以開始玩這兩種分頁方法了。如果你有任何問題,你也可以在我們的 Discord 伺服器上聯繫我們。