來源:Dcard Backend Team 如何讓工程師能更專注在列表排序與組合的演算法? | by Ruian | Dcard Tech Blog | May, 2022 | Medium
跟複雜的資料庫分頁說掰掰
作為一個致力讓所有人都能找到共鳴的平台,Dcard 不斷地在嘗試讓使用者能更快速的找到感興趣的內容。其中包含依據服務地區不同有不同的首頁文章列表、主題策展列表、即時熱門看板列表、精選看板列表,也有每個使用者專屬的追蹤列表、推薦文章列表,甚至連推薦通知都是。
這麼多各式各樣的列表要提供給使用者,Dcard Backend Team 現在已經可以讓 ML 與後端工程師能夠專注在製作列表,並且快速執行 A/B Testing 實驗來確認成效,不用太過煩惱其他問題。
但在 2019 年以前,Dcard 工程師們想要生出一個列表除了列表本身的邏輯外,還需要處理很多其他工程問題,例如在資料庫上處理分頁。
分頁問題
一次取回全部的資料對使用者跟伺服器來說都不現實,所以後端工程師或多或少都有處理過從一張資料表取回一部分資料的需求,也就是要做分頁。
為了避免全表掃描,後端工程師通常是依照過濾與排序的需求在資料庫建立 B+樹索引,然後搭配類似 SQL WHERE x ORDER BY y LIMIT z 去有效率的定位索引掃描位置並提前終止掃描。如同 PostgreSQL 文件中提到的:
An important special case is ORDER BY in combination with LIMIT n: an explicit sort will have to
process all the data to identify the first n rows, but if there is an index matching the ORDER BY, the first n rows can be retrieved directly, without scanning the remainder at all. https://www.postgresql.org/docs/14/indexes-ordering.html
Dcard 一直到 2019 年以前都依賴這個方法在做所有列表的分頁:後端工程師們為了不同的排序開始建立不同的索引;而有些更複雜的需求則要根據更多資料與條件來計算排序分數,就演變成了一個資料庫上面要花費大量珍貴的計算資源不停的更新許多的 Materialized Views。
但把資料在資料庫中排序好還沒完:每做一個列表,後端工程師們還需要處理大同小異的分頁 API 參數,例如 before、after、limit 等,去建構對應的資料庫查詢。在推出個人追蹤列表的時候,我們擔心原資料庫負擔太沈重所以開了獨立的資料庫出來,又更是整個重做了一次分頁 API ,工程非常浩大。
就算列表終於上線了也還沒結束:列表的排序與組合常常要根據實驗結果又甚至是外在隕石事件做調整,工程師們就又要重新處理索引、Materialized Views,甚至是重讀舊程式碼來修改分頁 API。常常花費數週都在處理分頁積累的工程問題,而非列表內容本身。
大家共用的 Key-Value 列表系統
其實 2018 年已經有感覺工程師要做一個列表的工實在太大了,但我們還有更多列表想要去嘗試,例如個人的文章推薦、通知推薦,而每個列表我們也想嘗試各種不同的排序。若改列表排序都需要花數天重新考慮資料庫索引或 Materialized Views 或分頁 API 參數修改等問題,那實在做不了幾個列表。
為了能讓任何 ML 與後端工程師在要做列表的時候都能專注在製作列表而非系統如何分頁,我們做了一個內部的列表 API,把列表都用簡單的 Linked List 來表示:每一頁都會指向下一頁。
如此一來分頁 API 以及儲存都變成單純的 Key-Value 形式,工程師能簡單地透過指向下一頁來控制列表內容順序。若有需要甚至也能用同樣的方式組合多個既有的列表。這個 API 也負責舊列表的清除,這樣作為列表工程師就只需要專注在實作新列表排序與組合邏輯的小程式,並讓它不斷去塞入新的列表即可,不用再煩惱原本那些分頁工程問題。
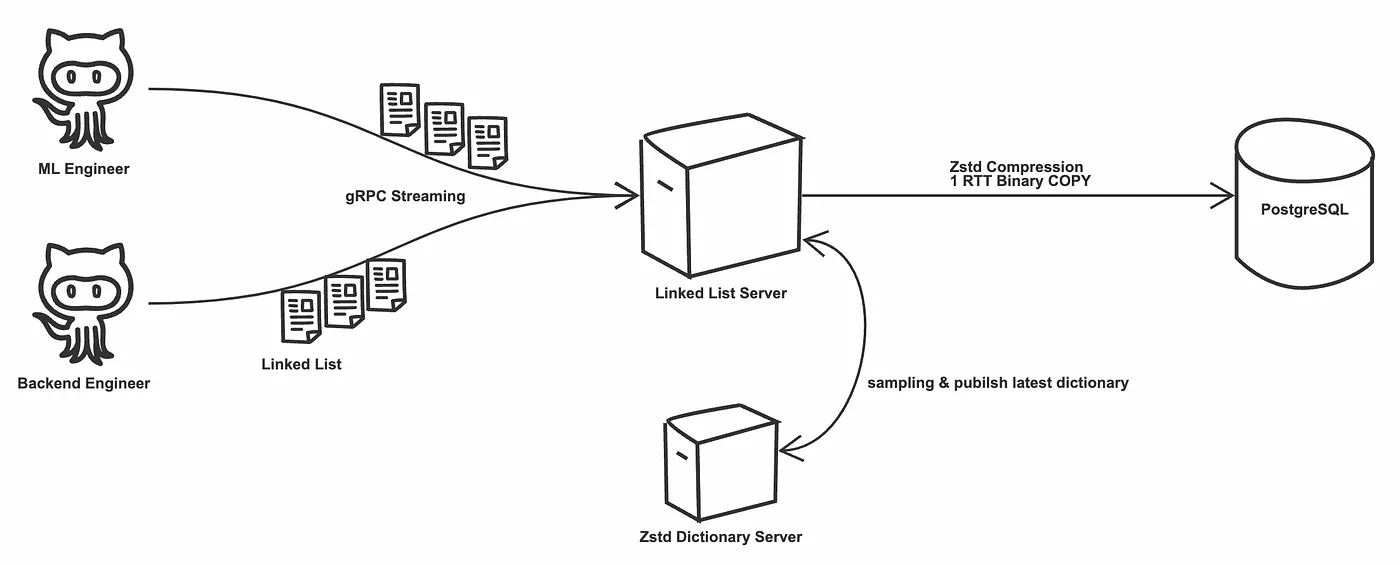
我們為了能讓工程師能真正無後顧之憂,針對這個系統的寫入路徑做了很多優化,讓它能撐起更多的寫入量:
-
盡可能減少不必要的 RTT:對工程師提供的內部 API 使用 gRPC Bidirectional Streaming,並幫工程師在 Streaming 上面做 Batch Copy 到背後的 PostgreSQL。我們也修改 PostgreSQL Client Library (pgx) 的 Copy 實作,確保每次 Copy 都是 1 RTT。
-
盡可能減少資料庫硬碟寫入量:我們在每一頁寫入資料庫之前會經過 zstd 壓縮。而為了確保它一直都有最好的壓縮率,我們在 Streaming API 之上會不斷的採樣原始資料來發布新的壓縮字典。
-
盡可能減少網路傳輸量:確保使用最佳的傳輸格式,詳細可以看另外一篇:PostgreSQL 使用 Extended Query Protocol 避免頻寬與效能浪費
若從 Disk Monitoring 來看,我們用一台 GCP n1-highmem-4 機器搭配 1TB Persistent SSD 可以撐起 120MiB/s 以上的寫入量,每天寫入超過 10TiB。
接下來呢?
這套內部系統從 2019 年開始用於服務 Dcard 上面各式各樣的列表,包含每個使用者的推薦列表,各地區、各看板的熱門列表,甚至是每個人的推薦通知也是經過這個內部系統做儲存。它成功讓工程師能夠簡單的修改邏輯就能快速生出另外一個不同排序組合的列表,再搭配 A/B Testing Remote Config Cookie + CDN Worker 就能讓我們保有 CDN 快取下快速進行各種實驗。
我們除了在探索新的模式外,目前對這個系統的需求也還在不斷增加,所以我們仍再不斷改進它:為了能支撐更多的寫入量,我們在 2022 年已經將原先的單台 n1-highmem-4 的 PostgreSQL 淘汰,改成多台可水平擴展的方案:目前可以承受每秒更新超過 3600 個列表,每秒新增超過 20000 個分頁。