
Photo by Tobias Fischer on Unsplash
👋 مقدمة
تُعد قاعدة البيانات (Database) أحد الأركان الأساسية لأي تطبيق. فهي المكان الذي تخزن فيه كل ما يحتاج تطبيقك إلى تذكره، أو حسابه لاحقاً، أو عرضه لمستخدمين آخرين عبر الإنترنت. كل شيء يسير على ما يرام حتى تنمو قاعدة البيانات ويبدأ تطبيقك في التأخر (Lag) لأنك كنت تحاول جلب وعرض 1000 منشور في وقت واحد. حسناً، أنت مهندس ذكي، أليس كذلك؟ تقوم بإصلاح ذلك بسرعة باستخدام زر “عرض المزيد”. بعد بضعة أسابيع، تواجه خطأ انتهاء المهلة (Timeout error) جديد! تتوجه إلى Stack Overflow ولكن سرعان ما تدرك أن مفتاحي Ctrl و V قد توقفا عن العمل بسبب الاستخدام المفرط 🤦 ومع عدم وجود خيارات أخرى تحت تصرفك، تبدأ فعلياً في التصحيح (Debugging) وتدرك أن قاعدة البيانات تعيد أكثر من 50,000 منشور في كل مرة يفتح فيها المستخدم تطبيقك! ماذا نفعل الآن؟

لمنع هذه السيناريوهات المروعة، يجب أن نكون على دراية بالمخاطر منذ البداية لأن المطور المستعد جيداً لن يضطر أبداً للمخاطرة. ستقوم هذه المقالة بإعدادك لمكافحة مشكلات الأداء المتعلقة بقاعدة البيانات باستخدام offset و cursor pagination.
“درهم وقاية خير من قنطار علاج.” - بنجامين فرانكلين
📚 ما هو تقسيم الصفحات (Pagination)؟
التقسيم (Pagination) هو استراتيجية تُستخدم عند الاستعلام عن أي مجموعة بيانات تحتوي على أكثر من بضع مئات من السجلات. بفضل التقسيم، يمكننا تقسيم مجموعة البيانات الكبيرة الخاصة بنا إلى أجزاء (أو صفحات) يمكننا جلبها وعرضها تدريجياً للمستخدم، وبالتالي تقليل الحمل على قاعدة البيانات. يحل التقسيم أيضاً الكثير من مشكلات الأداء في كل من جانب العميل (Client) والخادم (Server)! بدون التقسيم، سيتعين عليك تحميل سجل الدردشة بالكامل لمجرد قراءة أحدث رسالة أُرسلت إليك.
في هذه الأيام، أصبح التقسيم ضرورة تقريباً لأن كل تطبيق من المحتمل جداً أن يتعامل مع كميات كبيرة من البيانات. يمكن أن تكون هذه البيانات أي شيء بدءاً من المحتوى الذي ينشئه المستخدم، أو المحتوى المضاف من قبل المسؤولين أو المحررين، أو عمليات التدقيق والسجلات التي يتم إنشاؤها تلقائياً. بمجرد أن تنمو قائمتك إلى أكثر من بضعة آلاف من العناصر، ستستغرق قاعدة البيانات وقتاً طويلاً لحل كل طلب وسيتأثر سرعة وإمكانية الوصول إلى الواجهة الأمامية (Front-end). أما بالنسبة للمستخدمين، فستبدو تجربتهم شيئاً كهذا.

الآن بعد أن عرفنا ما هو التقسيم، كيف نستخدمه فعلياً؟ ولماذا هو ضروري؟
🔍 أنواع التقسيم
هناك استراتيجيتان للتقسيم تستخدمان على نطاق واسع - offset و cursor. قبل التعمق ومعرفة كل شيء عنهما، دعونا نلقي نظرة على بعض المواقع التي تستخدمهما.
أولاً، دعونا نزور صفحة Stargazer الخاصة بـ GitHub ونلاحظ كيف تشير علامة التبويب إلى 5,000+ وليس رقماً مطلقاً؟ أيضاً، بدلاً من أرقام الصفحات القياسية، يستخدمون أزرار Previous (السابق) و Next (التالي).

الآن، دعونا ننتقل إلى قائمة منتجات Amazon ونلاحظ العدد الدقيق للنتائج 364، و التقسيم القياسي مع جميع أرقام الصفحات التي يمكنك النقر خلالها 1 2 3 … 20.

من الواضح جداً أن عملاقي التكنولوجيا لم يتمكنا من الاتفاق على الحل الأفضل! لماذا؟ حسناً، سنحتاج إلى استخدام إجابة يكرهها المطورون: الأمر يعتمد. دعونا نستكشف كلتا الطريقتين لفهم مزاياهما وقيودهما وتأثيرهما على الأداء.
Offset pagination (التقسيم بالإزاحة)
تستخدم معظم مواقع الويب التقسيم بالإزاحة (Offset pagination) نظراً لبساطته ومدى كونه بديهياً للمستخدمين. لتنفيذ التقسيم بالإزاحة، سنحتاج عادةً إلى معلومتين:
limit- عدد الصفوف التي سيتم جلبها من قاعدة البياناتoffset- عدد الصفوف التي سيتم تخطيها. الإزاحة (Offset) تشبه رقم الصفحة، ولكن مع القليل من الرياضيات حولها(offset = (page-1) * limit)
للحصول على الصفحة الأولى من بياناتنا، نضع limit عند 10 (لأننا نريد 10 عناصر في الصفحة) و offset عند 0 (لأننا نريد بدء العد لـ 10 عناصر من العنصر رقم 0). نتيجة لذلك، سنحصل على عشرة صفوف.
للحصول على الصفحة الثانية، نحافظ على limit عند 10 (هذا لا يتغير لأننا نريد أن تحتوي كل صفحة على 10 صفوف) ونضع offset عند 10 (إرجاع النتائج من الصف العاشر فصاعداً). نستمر في هذا النهج، مما يسمح للمستخدم النهائي بالتنقل عبر النتائج وعرض كل محتواه.
في عالم SQL، سيتم كتابة استعلام مثل هذا كـ SELECT * FROM posts OFFSET 10 LIMIT 10.
تعرض بعض مواقع الويب التي تطبق التقسيم بالإزاحة أيضاً رقم الصفحة للصفحة الأخيرة. كيف يفعلون ذلك؟ جنباً إلى جنب مع نتائج كل صفحة، يميلون أيضاً إلى إرجاع سمة sum تخبرك بعدد الصفوف الموجودة إجمالياً. باستخدام limit و sum والقليل من الرياضيات، يمكنك حساب رقم الصفحة الأخيرة باستخدام lastPage = ceil(sum / limit)
بقدر ما تكون هذه الميزة مريحة للمستخدم، يواجه المطورون صعوبة في توسيع نطاق هذا النوع من التقسيم. بالنظر إلى سمة sum، يمكننا أن نرى بالفعل أن عد جميع الصفوف في قاعدة البيانات للوصول إلى الرقم الدقيق قد يستغرق وقتاً طويلاً. بجانب ذلك، يتم تنفيذ الإزاحة في قواعد البيانات بطريقة تتكرر عبر الصفوف لمعرفة عدد الصفوف التي يجب تخطيها. هذا يعني أنه كلما زادت الإزاحة لدينا، طالت مدة استعلام قاعدة البيانات الخاصة بنا.
الجانب السلبي الآخر للتقسيم بالإزاحة هو أنه لا يعمل بشكل جيد مع البيانات في الوقت الفعلي أو البيانات المتغيرة بشكل متكرر. تقول الإزاحة عدد الصفوف التي نريد تخطيها ولكنها لا تأخذ في الاعتبار حذف الصفوف أو إنشاء صفوف جديدة. قد تؤدي مثل هذه الإزاحة إلى عرض بيانات مكررة أو بعض البيانات المفقودة.
Cursor pagination (التقسيم بالمؤشر)
المؤشرات (Cursors) هي خلفاء للإزاحة، لأنها تحل جميع المشكلات التي يواجهها التقسيم بالإزاحة - الأداء، البيانات المفقودة، و تكرار البيانات لأنها لا تعتمد على الترتيب النسبي للصفوف كما هو الحال في التقسيم بالإزاحة. بدلاً من ذلك، تعتمد على فهرس (Index) مُنشأ وتديره قاعدة البيانات. لتنفيذ التقسيم بالمؤشر، سنحتاج إلى المعلومات التالية:
limit- كما كان من قبل، عدد الصفوف التي نريد عرضها في صفحة واحدةcursor- معرف (ID) عنصر مرجعي في القائمة. يمكن أن يكون هذاالعنصر الأولإذا كنت تستعلم عنالصفحة السابقةوالعنصر الأخيرإذا كنت تستعلم عنالصفحة التالية.cursorDirection- إذا نقر المستخدم على Next أو Previous (بعد أو قبل)
عند طلب الصفحة الأولى، لا نحتاج لتقديم أي شيء، فقط limit 10، للإشارة إلى عدد الصفوف التي نريد الحصول عليها. نتيجة لذلك، نحصل على صفوفنا العشرة.
للحصول على الصفحة التالية، نستخدم معرف الصف الأخير كـ cursor ونضبط cursorDirection إلى after.
وبالمثل، إذا أردنا الانتقال إلى الصفحة السابقة، نستخدم معرف الصف الأول كـ cursor ونضبط direction إلى before.
للمقارنة، في عالم SQL، يمكننا كتابة استعلامنا كـ SELECT * FROM posts WHERE id > 10 LIMIT 10 ORDER BY id DESC.
الاستعلامات التي تستخدم cursor بدلاً من offset تكون أكثر كفاءة لأن استعلام WHERE يساعد في تخطي الصفوف غير المرغوب فيها، بينما يحتاج OFFSET إلى التكرار عبرها، مما يؤدي إلى مسح كامل للجدول (full-table scan). يمكن أن يكون تخطي الصفوف باستخدام WHERE أسرع إذا قمت بإعداد فهارس مناسبة على المعرفات الخاصة بك. يتم إنشاء الفهرس بشكل افتراضي في حالة المفتاح الأساسي (primary key) الخاص بك.
ليس ذلك فحسب، لم تعد بحاجة إلى القلق بشأن إدراج أو حذف الصفوف. إذا كنت تستخدم إزاحة قدرها 10، فستتوقع وجود 10 صفوف بالضبط قبل صفحتك الحالية. إذا لم يتم استيفاء هذا الشرط، سيعيد استعلامك نتائج غير متسقة مما يؤدي إلى تكرار البيانات وحتى صفوف مفقودة. يمكن أن يحدث هذا إذا تم حذف أي من الصفوف قبل صفحتك الحالية أو إضافة صفوف جديدة. يحل التقسيم بالمؤشر هذه المشكلة باستخدام فهرس الصف الأخير الذي جلبته ويعرف بالضبط من أين يبدأ البحث، عندما تطلب المزيد.
الأمر ليس كله وردياً. التقسيم بالمؤشر مشكلة معقدة حقاً إذا كنت بحاجة إلى تنفيذها على الواجهة الخلفية بنفسك. لتنفيذ التقسيم بالمؤشر، ستحتاج إلى عبارات WHERE و ORDER BY في استعلامك. بالإضافة إلى ذلك، ستحتاج أيضاً إلى عبارات WHERE للتصفية حسب الشروط المطلوبة. يمكن أن يصبح هذا معقداً للغاية بسرعة كبيرة وقد ينتهي بك الأمر باستعلام متداخل ضخم. بجانب ذلك، ستحتاج أيضاً إلى إنشاء فهارس لجميع الأعمدة التي تحتاج إلى الاستعلام عنها.
رائع! لقد تخلصنا من التكرارات و البيانات المفقودة بالانتقال إلى التقسيم بالمؤشر! لكن لا تزال لدينا مشكلة واحدة متبقية. نظراً لأنك لا ينبغي أن تكشف عن المرفات الرقمية المتزايدة للمستخدم (لأسباب أمنية)، يجب عليك الآن الحفاظ على نسخة مشفرة (hashed version) لكل معرف. كلما احتجت الاستعلام من قاعدة البيانات، تقوم بتحويل معرف السلسلة هذا إلى معرفه الرقمي من خلال النظر في جدول يحتوي على هذه الأزواج. ماذا لو كان هذا الصف مفقوداً؟ ماذا لو نقرت على زر التالي، وأخذت معرف الصف الأخير، وطلبت الصفحة التالية، ولكن قاعدة البيانات لم تتمكن من العثور على المعرف؟
هذه حالة نادرة حقاً ولا تحدث إلا إذا تم حذف معرف الصف الذي توشك على استخدامه كمؤشر للتو. يمكننا حل هذه المشكلة عن طريق تجربة الصفوف السابقة أو جلب بيانات الطلبات السابقة مرة أخرى لتحديث الصف الأخير بمعرف جديد، ولكن كل ذلك يجلب مستوى جديداً تماماً من التعقيد، ويحتاج المطور إلى فهم عدد من المفاهيم الجديدة، مثل العودية (recursion) و إدارة الحالة المناسبة. لحسن الحظ، تهتم خدمات مثل Appwrite بذلك، لذا يمكنك فقط استخدام التقسيم بالمؤشر كميزة.
🚀 التقسيم في Appwrite
Appwrite هو backend-as-a-service مفتوح المصدر يجرد كل التعقيدات التي ينطوي عليها بناء تطبيق حديث من خلال تزويدك بمجموعة من واجهات برمجة تطبيقات REST لاحتياجات الواجهة الخلفية الأساسية الخاصة بك. يتعامل Appwrite مع مصادقة المستخدم والترخيص، وقواعد البيانات، وتخزين الملفات، والوظائف السحابية (cloud functions)، و webhooks، والمزيد! إذا كان هناك شيء مفقود، يمكنك توسيع Appwrite باستخدام لغة الواجهة الخلفية المفضلة لديك.
تسمح لك قاعدة بيانات Appwrite بتخزين أي بيانات نصية تحتاج إلى مشاركتها بين المستخدمين. تتيح لك قاعدة بيانات Appwrite إنشاء مجموعات (جداول) متعددة وتخزين مستندات (صفوف) متعددة فيها. تحتوي كل مجموعة على سمات (أعمدة) مهيأة لمنح مجموعة البيانات الخاصة بك مخططاً (schema) مناسباً. يمكنك أيضاً تكوين الفهارس لجعل استعلامات البحث الخاصة بك أكثر كفاءة. عند قراءة بياناتك، يمكنك استخدام مجموعة من الاستعلامات القوية، وتصفيتها، وفرزها، والحد من عدد النتائج، وتقسيمها لصفحات. وكل هذا يأتي جاهزاً للاستخدام!
ما يجعل قاعدة بيانات Appwrite أفضل هو دعم Appwrite للتقسيم، حيث ندعم كلاً من التقسيم بالإزاحة وبالمؤشر! لنتخيل أن لدينا مجموعة بالمعرف articles، يمكننا الحصول على المستندات من هذه المجموعة إما بتقسيم الإزاحة أو المؤشر:
// Setup
import { Appwrite, Query } from "appwrite";
const sdk = new Appwrite();
sdk
.setEndpoint('https://demo.appwrite.io/v1') // Your API Endpoint
.setProject('articles-demo') // Your project ID
;
// Offset pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
500, // Offset, amount of documents to skip
).then((response) => {
console.log(response);
});
// Cursor pagination
sdk.database.listDocuments(
'articles', // Collection ID
[ Query.equal('status', 'published') ], // Filters
10, // Limit
undefined, // Not using offset
'61d6eb2281fce3650c2c' // ID of document I want to paginate after
).then((response) => {
console.log(response);
});
أولاً، نقوم باستيراد مكتبة Appwrite SDK ونقوم بإعداد مثيل متصل بمثيل Appwrite محدد ومشروع محدد. ثم، نقوم بإدراج 10 مستندات باستخدام التقسيم بالإزاحة مع وجود مرشح لإظهار المستندات المنشورة فقط. بعد ذلك مباشرة، نكتب نفس استعلام إدراج المستندات تماماً، ولكن هذه المرة باستخدام تقسيم cursor بدلاً من offset.
📊 معايير الأداء (Benchmarks)
لقد استخدمنا كلمة الأداء في كثير من الأحيان في هذه المقالة دون تقديم أي أرقام حقيقية، لذا دعونا ننشئ معياراً معاً! سنستخدم Appwrite كخادم الواجهة الخلفية لدينا لأنه يدعم كلاً من التقسيم بالإزاحة وبالمؤشر و Node.JS لكتابة نصوص المعايرة. ففي النهاية، من السهل جداً متابعة Javascript.
يمكنك العثور على كود المصدر الكامل في مستودع GitHub.
أولاً، نقوم بإعداد Appwrite، وتسجيل مستخدم، وإنشاء مشروع، وإنشاء مجموعة تسمى posts مع إذن مستوى المجموعة وإذن القراءة مضبوطاً على role:all. لمعرفة المزيد حول هذه العملية، قم بزيارة وثائق Appwrite. يجب أن يكون لدينا الآن Appwrite جاهزاً للاستخدام.
لا يمكننا إجراء المعايرة بعد، لأن قاعدة البيانات لدينا فارغة! دعونا نملأ جدولنا ببعض البيانات. نستخدم النص البرمجي التالي لتحميل البيانات في قاعدة بيانات MariadDB الخاصة بنا والاستعداد للمعايرة.
const config = {};
// Don't forget to fill config variable with secret information
console.log("🤖 Connecting to database ...");
const connection = await mysql.createConnection({
host: config.mariadbHost,
port: config.mariadbPost,
user: config.mariadbUser,
password: config.mariadbPassword,
database: `appwrite`,
});
const promises = [];
console.log("🤖 Database connection established");
console.log("🤖 Preparing database queries ...");
let index = 1;
for(let i = 0; i < 100; i++) {
const queryValues = [];
for(let l = 0; l < 10000; l++) {
queryValues.push(`('id${index}', '[]', '[]')`);
index++;
}
const query = `INSERT INTO _project_${config.projectId}_collection_posts (_uid, _read, _write) VALUES ${queryValues.join(", ")}`;
promises.push(connection.execute(query));
}
console.log("🤖 Pushing data. Get ready, this will take quite some time ...");
await Promise.all(promises);
console.error(`🌟 Successfully finished`);
استخدمنا طبقتين من حلقات for لزيادة سرعة النص البرمجي. تقوم حلقة for الأولى بإنشاء عمليات تنفيذ الاستعلام التي يجب انتظارها، وتقوم الحلقة الثانية بإنشاء استعلام طويل يحتوي على طلبات إدراج متعددة. بشكل مثالي، نود أن يكون كل شيء في طلب واحد، ولكن هذا مستحيل بسبب تكوين MySQL، لذلك قمنا بتقسيمه إلى 100 طلب.
لدينا مليون مستند تم إدراجه في أقل من دقيقة، ونحن مستعدون لبدء معاييرنا. سنستخدم مكتبة اختبار الحمل k6 لهذا العرض التوضيحي.
دعونا نعاير Offset pagination المعروفة والمستخدمة على نطاق واسع أولاً. خلال كل سيناريو اختبار، نحاول جلب صفحة بها 10 مستندات، من أجزاء مختلفة من مجموعة البيانات الخاصة بنا. سنبدأ بإزاحة 0 ونذهب حتى إزاحة 900k بزيادات قدرها 100k. تمت كتابة المعيار بطريقة تجعله يقدم طلباً واحداً فقط في المرة الواحدة ليكون دقيقاً قدر الإمكان. سنقوم أيضاً بتشغيل نفس المعيار عشر مرات وقياس متوسط أوقات الاستجابة لضمان الأهمية الإحصائية. سنستخدم عميل HTTP الخاص بـ k6 لتقديم طلبات إلى واجهة برمجة تطبيقات REST الخاصة بـ Appwrite.
// script_offset.sh
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?offset=${__ENV.OFFSET}&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
لتشغيل المعيار بتكوينات إزاحة مختلفة وتخزين الناتج في ملفات CSV، قمت بإنشاء نص برمجي bash بسيط. ينفذ هذا النص البرمجي k6 عشر مرات، مع تكوين إزاحة مختلف في كل مرة. سيتم توفير الناتج كإخراج وحدة التحكم (console output).
#!/bin/bash
# benchmark_offset.sh
k6 -e OFFSET=0 run script.js
k6 -e OFFSET=100000 run script.js
k6 -e OFFSET=200000 run script.js
k6 -e OFFSET=300000 run script.js
k6 -e OFFSET=400000 run script.js
k6 -e OFFSET=500000 run script.js
k6 -e OFFSET=600000 run script.js
k6 -e OFFSET=700000 run script.js
k6 -e OFFSET=800000 run script.js
k6 -e OFFSET=900000 run script.js
في غضون دقيقة، انتهت جميع المعايير وزودتني بـ متوسط وقت الاستجابة لكل تكوين إزاحة. كانت النتائج كما هو متوقع ولكنها غير مرضية على الإطلاق.
| Offset pagination (ms) | |
|---|---|
| 0% offset | 3.73 |
| 10% offset | 52.39 |
| 20% offset | 96.83 |
| 30% offset | 144.13 |
| 40% offset | 216.06 |
| 50% offset | 257.71 |
| 60% offset | 313.06 |
| 70% offset | 371.03 |
| 80% offset | 424.63 |
| 90% offset | 482.71 |
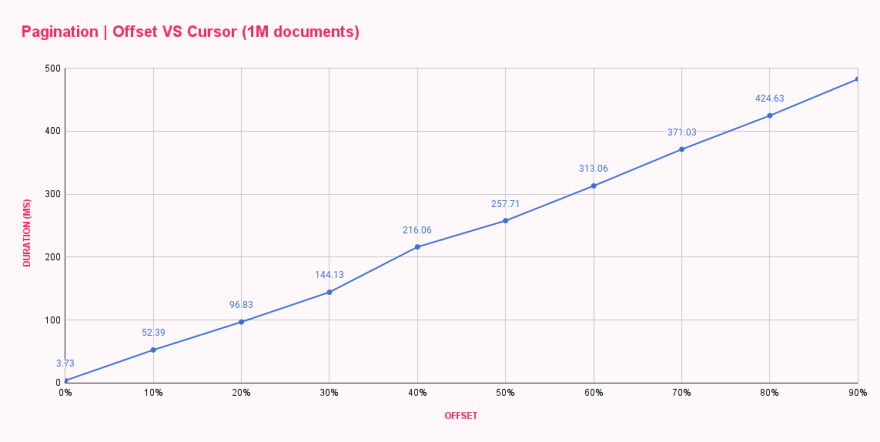
كما نرى، كان offset 0 سريعاً جداً، حيث استجاب في أقل من 4ms. كانت قفزتنا الأولى إلى offset 100k، وكان التغيير جذرياً، مما زاد أوقات الاستجابة إلى 52ms. مع كل زيادة في الإزاحة، زادت المدة، مما أدى إلى ما يقرب من 500ms للحصول على عشرة مستندات بعد إزاحة 900k مستند. هذا جنون!
الآن دعونا نحدث النص البرمجي الخاص بنا لاستخدام Cursor pagination. سنقوم بتحديث النص البرمجي الخاص بنا لاستخدام مؤشر بدلاً من الإزاحة وتحديث نص bash الخاص بنا لتوفير مؤشر (معرف المستند) بدلاً من رقم الإزاحة.
// script_cursor.js
import http from 'k6/http';
// Before running, make sure to run setup.js
export const options = {
iterations: 10,
summaryTimeUnit: "ms",
summaryTrendStats: ["avg"]
};
const config = JSON.parse(open("config.json"));
export default function () {
http.get(`${config.endpoint}/database/collections/posts/documents?cursor=${__ENV.CURSOR}&cursorDirection=after&limit=10`, {
headers: {
'content-type': 'application/json',
'X-Appwrite-Project': config.projectId
}
});
}
#!/bin/bash
# benchmark_cursor.sh
k6 -e CURSOR=id1 run script_cursor.js
k6 -e CURSOR=id100000 run script_cursor.js
k6 -e CURSOR=id200000 run script_cursor.js
k6 -e CURSOR=id300000 run script_cursor.js
k6 -e CURSOR=id400000 run script_cursor.js
k6 -e CURSOR=id500000 run script_cursor.js
k6 -e CURSOR=id600000 run script_cursor.js
k6 -e CURSOR=id700000 run script_cursor.js
k6 -e CURSOR=id800000 run script_cursor.js
k6 -e CURSOR=id900000 run script_cursor.js
بعد تشغيل النص البرمجي، يمكننا بالفعل معرفة أن هناك زيادة في الأداء حيث كانت هناك اختلافات ملحوظة في أوقات الاستجابة. لقد وضعنا النتائج في جدول لمقارنة طريقتي التقسيم هاتين جنباً إلى جنب.
| Offset pagination (ms) | Cursor pagination (ms) | |
|---|---|---|
| 0% offset | 3.73 | 6.27 |
| 10% offset | 52.39 | 4.07 |
| 20% offset | 96.83 | 5.15 |
| 30% offset | 144.13 | 5.29 |
| 40% offset | 216.06 | 6.65 |
| 50% offset | 257.71 | 7.26 |
| 60% offset | 313.06 | 4.61 |
| 70% offset | 371.03 | 6.00 |
| 80% offset | 424.63 | 5.60 |
| 90% offset | 482.71 | 5.05 |
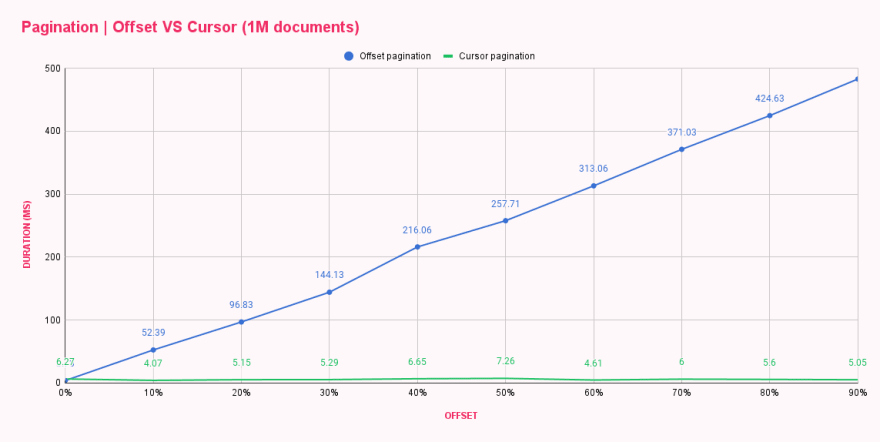
رائع! Cursor pagination رائع! يوضح الرسم البياني أن التقسيم بالمؤشر لا يهتم بـ حجم الإزاحة، وكل استعلام يكون بنفس كفاءة الاستعلام الأول أو الأخير. هل يمكنك تخيل مقدار الضرر الذي يمكن أن يحدث بتحميل الصفحة الأخيرة من قائمة ضخمة بشكل متكرر؟ 😬
إذا كنت مهتماً بتشغيل الاختبارات على جهازك الخاص، فيمكنك العثور على كود المصدر الكامل كمستودع GitHub. يتضمن المستودع ملف README.md يشرح عملية التثبيت وتشغيل النصوص البرمجية بالكامل.
👨🎓 ملخص
تقدم Offset pagination طريقة تقسيم معروفة جيداً حيث يمكنك رؤية أرقام الصفحات والنقر خلالها. تأتي هذه الطريقة البديهية مع مجموعة من الجوانب السلبية، مثل الأداء المروع مع الإزاحة العالية وإمكانية تكرار البيانات و فقدان البيانات.
تحل Cursor pagination كل هذه المشاكل وتجلب نظام تقسيم موثوقاً وسريعاً ويمكنه التعامل مع البيانات في الوقت الفعلي (التي تتغير بشكل متكرر). الجانب السلبي للتقسيم بالمؤشر هو عدم عرض أرقام الصفحات، وتعقيد تنفيذه، ومجموعة جديدة من التحديات للتغلب عليها، مثل معرفات المؤشر المفقودة.
الآن بالعودة إلى سؤالنا الأصلي، لماذا يستخدم GitHub Cursor pagination، لكن Amazon قررت استخدام Offset pagination؟ الأداء ليس دائماً المفتاح… تجربة المستخدم أكثر قيمة بكثير من عدد الخوادم التي يتعين على عملك دفع ثمنها.
أعتقد أن Amazon قررت استخدام الإزاحة لأنها تحسن تجربة المستخدم (UX)، ولكن هذا موضوع لبحث آخر. يمكننا أن نلاحظ بالفعل أننا إذا زرنا amazon.com وبحثنا عن قلم، فإنه يقول أن هناك 10,000 نتيجة بالضبط، ولكن لا يمكنك زيارة سوى الصفحات السبعة الأولى (350 نتيجة).
أولاً، هناك أكثر من 10 آلاف نتيجة، لكن Amazon تحد منها. ثانياً، يمكنك زيارة الصفحات السبعة الأولى على أي حال. إذا حاولت زيارة الصفحة 8، فستظهر خطأ 404. كما نرى، تدرك Amazon أداء Offset pagination لكنها قررت الاحتفاظ بها لأن قاعدة المستخدمين الخاصة بها تفضل رؤية أرقام الصفحات. كان عليهم تضمين بعض الحدود، ولكن من يذهب إلى الصفحة 100 من نتائج البحث على أي حال؟ 🤷
هل تعرف ما هو أفضل من القراءة عن التقسيم؟ تجربته! أشجعك على تجربة كلا الطريقتين لأنه من الأفضل الحصول على خبرة مباشرة. يستغرق إعداد Appwrite أقل من بضع دقائق، ويمكنك البدء في اللعب بكلتا طريقتي التقسيم. إذا كان لديك أي أسئلة، يمكنك أيضاً التواصل معنا على خادم Discord الخاص بنا.